6 Introduction R/Bioconductor
# mkdir data
wget https://s3-us-west-2.amazonaws.com/10x.files/samples/cell/pbmc3k/pbmc3k_filtered_gene_bc_matrices.tar.gz -O data/pbmc3k_filtered_gene_bc_matrices.tar.gz
cd data; tar -xzf pbmc3k_filtered_gene_bc_matrices.tar.gz
cd ..6.1 Start Environment
6.1.1 Local Command
full command
## maybe take away the --rm so they can save the container for later
## run from your home directory
cd 2020scworkshop
## example for user17
docker run --rm -it \
-e DISABLE_AUTH=true \
-v $PWD:/home/rstudio/materials \
-p 8787:8787 kdgosik/2020scworkshopExplaination of commands
- docker: command to run docker
- run: asking docker to run a container
- --rm: flag to remove the container when you exit from it
- nothing will be saved from your session to access again later
- this flag can be removed to keep container
- -it: flag to run the container interactively
- - this will keep all session output displaying on the terminal
- - to stop container go to terminal and press Crtl+c
- -v $PWD:/home/rstudio: map your home directory to a directory inside docker container called home/rstudio
- -p 8787:8787: map docker container port of 8787(rstudio port default) to your computer port 8787
- kdgosik/2020scworkshop: the image to run. It will be the image into a container if not already built on your computer
- [image link](https://hub.docker.com/r/kdgosik/2020scworkshop)6.1.2 AWS Command
## maybe take away the --rm so they can save the container for later
## run from your home directory
cd 2020scworkshop
## example for user17
docker run --rm -it \
-e PASSWORD=train \
-v $PWD:/home/rstudio/materials \
-p 9017:8787 kdgosik/2020scworkshopExplaination of commands
- docker: command to run docker
- run: asking docker to run a container
- --rm: flag to remove the container when you exit from it
- nothing will be saved from your session to access again later
- this flag can be removed to keep container
- -it: flag to run the container interactively
- - this will keep all session output displaying on the terminal
- - to stop container go to terminal and press Crtl+c
- -v $PWD:/home/rstudio/materials: map your home directory to a directory inside docker container called home/rstudio
- -p 9017:8787: map docker container port of 8787(rstudio port default) to your computer port 9017
- kdgosik/2020scworkshop: the image to run. It will be the image into a container if not already built on your computer
- [image link](https://hub.docker.com/r/kdgosik/2020scworkshop)- localhost:9017 or on AWS
- ec2-
.us-west-2.compute.amazonaws.com:$PORT_NUMBER ec2-54-202-32-102.us-west-2.compute.amazonaws.com:9017
- R/Rstudio parts
- Data Types and classes
- Packages and where to get them
- S3 vs S4
Visualizations and ggplot
- Installing packages
- Data-types
- Data manipulation, slicing
- Strings manipulations
- Introducing object oriented programming / S4 objects
- Visualization tools
- Bonus create FeaturePlot from Seurat in base ggplot
Bonus: run RSEM on Dana’s bam files if you are bored
6.2 Installing packages
6.2.1 CRAN
The Comprehensive R Archive Network CRAN is the biggest archive of R packages. There are few requirements for uploading packages besides building and installing succesfully, hence documentation and support is often minimal and figuring how to use these packages can be a challenge it itself. CRAN is the default repository R will search to find packages to install:
6.2.2 Github
Github isn’t specific to R, any code of any type in any state can be uploaded. There is no guarantee a package uploaded to github will even install, nevermind do what it claims to do. R packages can be downloaded and installed directly from github using the “devtools” package installed above.
## username/repository
devtools::install_github("satijalab/seurat") # latest stable version of Seurat packageGithub is also a version control system which stores multiple versions of any package. By default the most recent “master” version of the package is installed. If you want an older version or the development branch this can be specified using the “ref” parameter:
# different branch
devtools::install_github("satijalab/seurat", ref="release3.0")
# previous commit
## Merge branch 'develop' into feat/MultiModal
## - Shiwei Zheng committed on Jul 2, 2018
devtools::install_github("tallulandrews/M3Drop", ref="551014f488770627ab154a62e59d49df5df98a3f")Note: make sure you re-install the M3Drop master branch for later in the course.
6.2.3 Bioconductor
Bioconductor is a repository of R-packages specifically for biological analyses. It has the strictest requirements for submission, including installation on every platform and full documentation with a tutorial (called a vignette) explaining how the package should be used. Bioconductor also encourages utilization of standard data structures/classes and coding style/naming conventions, so that, in theory, packages and analyses can be combined into large pipelines or workflows.
Bioconductor also requires creators to support their packages and has a regular 6-month release schedule. Make sure you are using the most recent release of bioconductor before trying to install packages for the course.
6.2.4 Source
The final way to install packages is directly from source. In this case you have to download a fully built source code file, usually packagename.tar.gz, or clone the github repository and rebuild the package yourself. Generally this will only be done if you want to edit a package yourself, or if for some reason the former methods have failed. You can also get previous packages that aren’t supported any more on the CRAN package archive
6.3 Installation instructions:
All the packages necessary for this course are available here. A list of the packages will be on the README.md for the repository. A script is also available inside the docker/install.R file.
6.3.1 Classes/Types
R is a high level language so the underlying data-type is generally not important. The exception if you are accessing R data directly using another language such as C, but that is beyond the scope of this course. Instead we will consider the basic data classes: numeric, integer, logical, and character, and the higher level data class called “factor”. You can check what class your data is using the “class()” function.
6.3.1.1 Integer
## [1] "numeric"## [1] FALSE## [1] TRUE## [1] TRUE## [1] "numeric"## [1] 46.3.1.2 Numeric
## [1] "numeric"## [1] TRUE## [1] FALSE## [1] TRUE## [1] 16.3.1.3 Logical/ Boolean
The logical class stores boolean truth values, i.e. TRUE and FALSE. It is used for storing the results of logical operations and conditional statements will be coerced to this class. Most other data-types can be coerced to boolean without triggering (or “throwing”) error messages, which may cause unexpected behaviour.
## [1] "logical"## [1] TRUE6.3.2 Data structures
- Homogeneous
- 1D: atomic vector
- 2D: matrix
- nD: array
- Heterogeneous
- 1D: list
- 2D: data.frame
6.3.2.1 Character Vectors
## assign a character vector with c() operator
character_vector <- c("A", "C", "T", "G", "C", "T", "G", "C", "G", "A", "T", "G", "A", "C", "G", "A", "C")
## check class
class(character_vector)## [1] "character"## access the 3rd element with [] operator
## *note*: R is index starts at 1 (other programming languages start at 0)
character_vector[3]## [1] "T"## [1] "T" "G" "C" "T"## [1] "A" "G" "G" "A"## [1] "A" "A" "A" "A"6.3.2.2 Numeric Vector
The “numeric” class is the default class for storing any numeric data - integers, decimal numbers, numbers in scientific notation, etc…
## assign a character vector with c() operator
numeric_vector <- c(1, 5, 21, 17, 98, 35, 11, 13)
## check class
class(numeric_vector)## [1] "numeric"## [1] 98## [1] 5 21 17## backticks ` ` allow you to give names with non-typical characters
`numeric?_vector` <- c("A", 1, 5, 21, 17, 98, 35, 11, 13)
## check vector
`numeric?_vector`## [1] "A" "1" "5" "21" "17" "98" "35" "11" "13"## [1] "character"6.3.2.3 Factor Vector
String/Character data is very memory inefficient to store, each letter generally requires the same amount of memory as any integer. Thus when storing a vector of strings with repeated elements it is more efficient assign each element to an integer and store the vector as integers and an additional string-to-integer association table. Thus, by default R will read in text columns of a data table as factors.
## [1] 1 5 21 17 98 35 11 13
## Levels: 1 5 11 13 17 21 35 986.3.2.4 Named Vector
## Patient1 Patient2 Patient3 Patient4 Patient5 Patient6 Patient7 Patient8
## 1 5 21 17 98 35 11 136.3.2.5 List
## change the c() operator to list() operator
new_list <- list("A", 1, 5, 21, 17, 98, 35, 11, 13)
new_list## [[1]]
## [1] "A"
##
## [[2]]
## [1] 1
##
## [[3]]
## [1] 5
##
## [[4]]
## [1] 21
##
## [[5]]
## [1] 17
##
## [[6]]
## [1] 98
##
## [[7]]
## [1] 35
##
## [[8]]
## [1] 11
##
## [[9]]
## [1] 13## [1] 1## $Patient1
## [1] "A"
##
## $Patient2
## [1] 1
##
## $Patient3
## [1] 5
##
## $Patient4
## [1] 21
##
## $Patient5
## [1] 17
##
## $Patient6
## [1] 98
##
## $Patient7
## [1] 35
##
## $Patient8
## [1] 11
##
## $Patient9
## [1] 13## [1] 1- 2D
6.3.2.6 matrix
Create Matrix
## create numeric matrix
numeric_matrix <- matrix(sample(1:10, 100, replace = TRUE), nrow = 10, ncol = 10)
class(numeric_matrix) ## check class## [1] "matrix"Check Structure
## int [1:10, 1:10] 2 7 5 1 10 6 8 7 7 2 ...Get 3rd Row
## [1] 5 2 3 9 6 3 8 9 3 5Get 4th Column
## [1] 1 6 9 6 4 10 9 4 4 66.3.2.7 data.frame
Get data.frame
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosaCheck Class
## [1] "data.frame"Check Structure
## 'data.frame': 150 obs. of 5 variables:
## $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
## $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
## $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
## $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
## $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...Get 3rd Row
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 3 4.7 3.2 1.3 0.2 setosaGet 4th Column
## [1] 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 0.2 0.2 0.1 0.1 0.2 0.4 0.4 0.3
## [19] 0.3 0.3 0.2 0.4 0.2 0.5 0.2 0.2 0.4 0.2 0.2 0.2 0.2 0.4 0.1 0.2 0.2 0.2
## [37] 0.2 0.1 0.2 0.2 0.3 0.3 0.2 0.6 0.4 0.3 0.2 0.2 0.2 0.2 1.4 1.5 1.5 1.3
## [55] 1.5 1.3 1.6 1.0 1.3 1.4 1.0 1.5 1.0 1.4 1.3 1.4 1.5 1.0 1.5 1.1 1.8 1.3
## [73] 1.5 1.2 1.3 1.4 1.4 1.7 1.5 1.0 1.1 1.0 1.2 1.6 1.5 1.6 1.5 1.3 1.3 1.3
## [91] 1.2 1.4 1.2 1.0 1.3 1.2 1.3 1.3 1.1 1.3 2.5 1.9 2.1 1.8 2.2 2.1 1.7 1.8
## [109] 1.8 2.5 2.0 1.9 2.1 2.0 2.4 2.3 1.8 2.2 2.3 1.5 2.3 2.0 2.0 1.8 2.1 1.8
## [127] 1.8 1.8 2.1 1.6 1.9 2.0 2.2 1.5 1.4 2.3 2.4 1.8 1.8 2.1 2.4 2.3 1.9 2.3
## [145] 2.5 2.3 1.9 2.0 2.3 1.8Get 3rd Row
## [1] 5 2 3 9 6 3 8 9 3 5Get Species Variable
## [1] setosa setosa setosa setosa setosa setosa
## [7] setosa setosa setosa setosa setosa setosa
## [13] setosa setosa setosa setosa setosa setosa
## [19] setosa setosa setosa setosa setosa setosa
## [25] setosa setosa setosa setosa setosa setosa
## [31] setosa setosa setosa setosa setosa setosa
## [37] setosa setosa setosa setosa setosa setosa
## [43] setosa setosa setosa setosa setosa setosa
## [49] setosa setosa versicolor versicolor versicolor versicolor
## [55] versicolor versicolor versicolor versicolor versicolor versicolor
## [61] versicolor versicolor versicolor versicolor versicolor versicolor
## [67] versicolor versicolor versicolor versicolor versicolor versicolor
## [73] versicolor versicolor versicolor versicolor versicolor versicolor
## [79] versicolor versicolor versicolor versicolor versicolor versicolor
## [85] versicolor versicolor versicolor versicolor versicolor versicolor
## [91] versicolor versicolor versicolor versicolor versicolor versicolor
## [97] versicolor versicolor versicolor versicolor virginica virginica
## [103] virginica virginica virginica virginica virginica virginica
## [109] virginica virginica virginica virginica virginica virginica
## [115] virginica virginica virginica virginica virginica virginica
## [121] virginica virginica virginica virginica virginica virginica
## [127] virginica virginica virginica virginica virginica virginica
## [133] virginica virginica virginica virginica virginica virginica
## [139] virginica virginica virginica virginica virginica virginica
## [145] virginica virginica virginica virginica virginica virginica
## Levels: setosa versicolor virginica6.3.3 Detour to S3/S4
- S3 most of R uses
- Bioconductor requires R packages to be written as S4 objects
- OO field guide
- Closer to a typical programming language
- Classes/Methods and Generics
- Lots of Generics implemented for Bioinformatics!
Different way to access values. Need to use the @ symbol instead of $
- (@ is equivalent to $, and slot() to [[.)
6.3.3.1 Sparse Matrix
Triplet format for storing a matrix row, column, value i, p, x
Different from base R. Uses the S4 methods that Bioconductor uses.
ith row - 1
pth column - 1
value
Get First Value
dense matrix
Get First Value
6.3.3.2 Functions
6.4 More information
You can get more information about any R commands relevant to these datatypes using by typing ?function in an interactive session.
6.4.1 Checking for help for any function!
- start with a ? (this indicates you need the help menu)
- then the function name to get help on
6.5 Grammer of Graphics (ggplot2)
6.5.1 What is ggplot2?
ggplot2 is an R package designed by Hadley Wickham which facilitates data plotting. In this lab, we will touch briefly on some of the features of the package. If you would like to learn more about how to use ggplot2, we would recommend reading “ggplot2 Elegant graphics for data analysis”, by Hadley Wickham or checking out his original paper on the package
- Data: Always start with the data, identify the dimensions you want to visualize.
- Aesthetics: Confirm the axes based on the data dimensions, positions of various data points in the plot. Also check if any form of encoding is needed including size, shape, color and so on which are useful for plotting multiple data dimensions.
- Scale: Do we need to scale the potential values, use a specific scale to represent multiple values or a range?
- Geometric objects: These are popularly known as ‘geoms’. This would cover the way we would depict the data points on the visualization. Should it be points, bars, lines and so on?
- Statistics: Do we need to show some statistical measures in the visualization like measures of central tendency, spread, confidence intervals?
- Facets: Do we need to create subplots based on specific data dimensions?
- Coordinate system: What kind of a coordinate system should the visualization be based on — should it be cartesian or polar?

6.5.2 Principles of ggplot2
- Your data must be a dataframe if you want to plot it using ggplot2.
- Use the
aesmapping function to specify how variables in the dataframe map to features on your plot Use geoms to specify how your data should be represented on your graph eg. as a scatterplot, a barplot, a boxplot etc.
- Data: Always start with the data, identify the dimensions you want to visualize.
library(Seurat)
library(ggplot2)
gbm <- pbmc_small@assays$RNA@data
gbm <- as.data.frame(as.matrix(t(gbm)))
new_plot <- ggplot(gbm)- Aesthetics: Confirm the axes based on the data dimensions, positions of various data points in the plot. Also check if any form of encoding is needed including size, shape, color and so on which are useful for plotting multiple data dimensions.
1D Plots
Scale: Do we need to scale the potential values, use a specific scale to represent multiple values or a range?
Geometric objects: These are popularly known as ‘geoms’. This would cover the way we would depict the data points on the visualization. Should it be points, bars, lines and so on?
## ggplot(gbm, aes(x = MS4A1)) + geom_histogram()
## or
## new_plot_1dx <- new_plot_1dx + geom_histogram() ## reassign
new_plot_1dx + geom_histogram()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.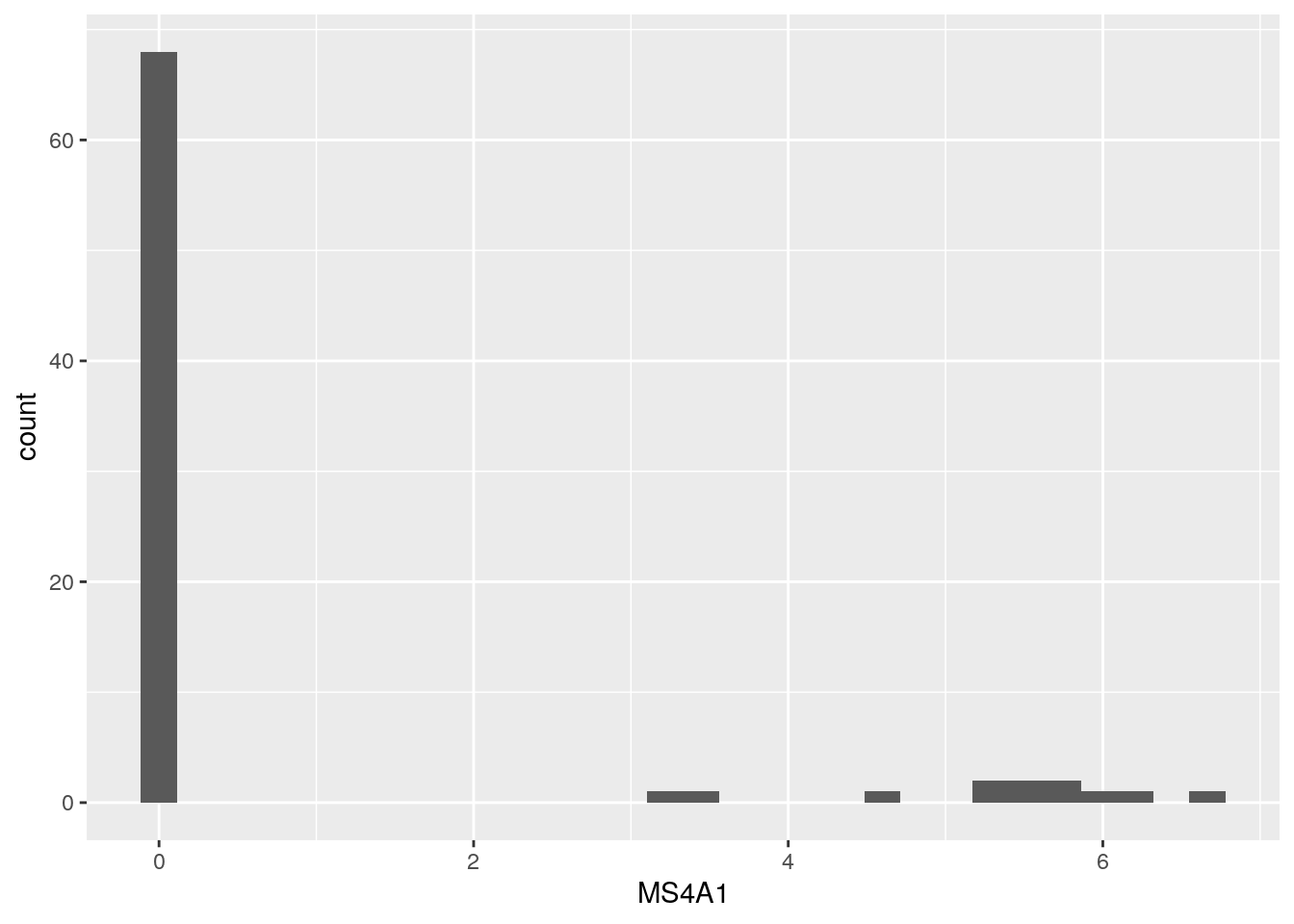
6.5.2.1 Lab A
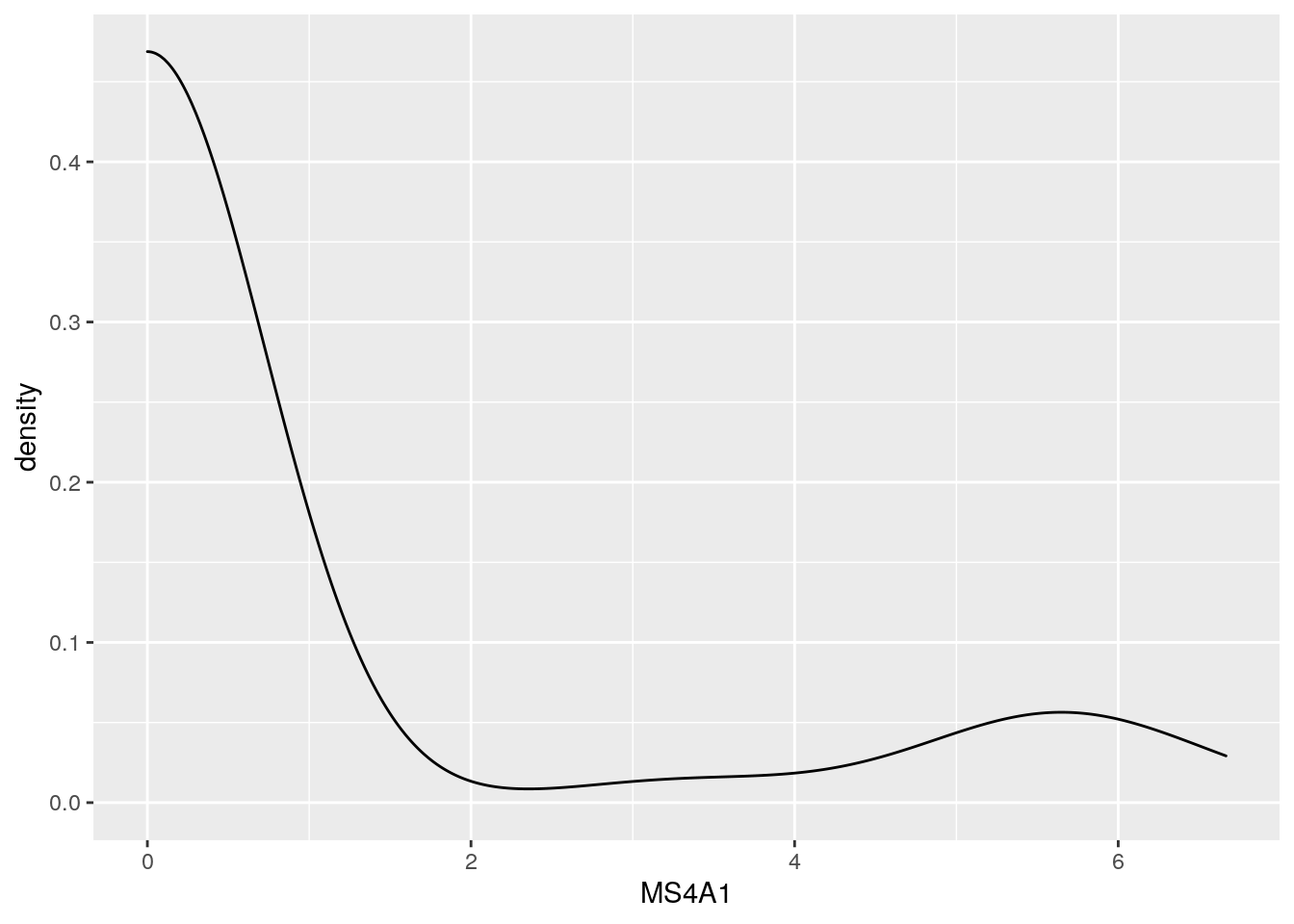
Use different geom_ to make a different plots - try _bar() - try _density()
- Statistics: Do we need to show some statistical measures in the visualization like measures of central tendency, spread, confidence intervals?
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.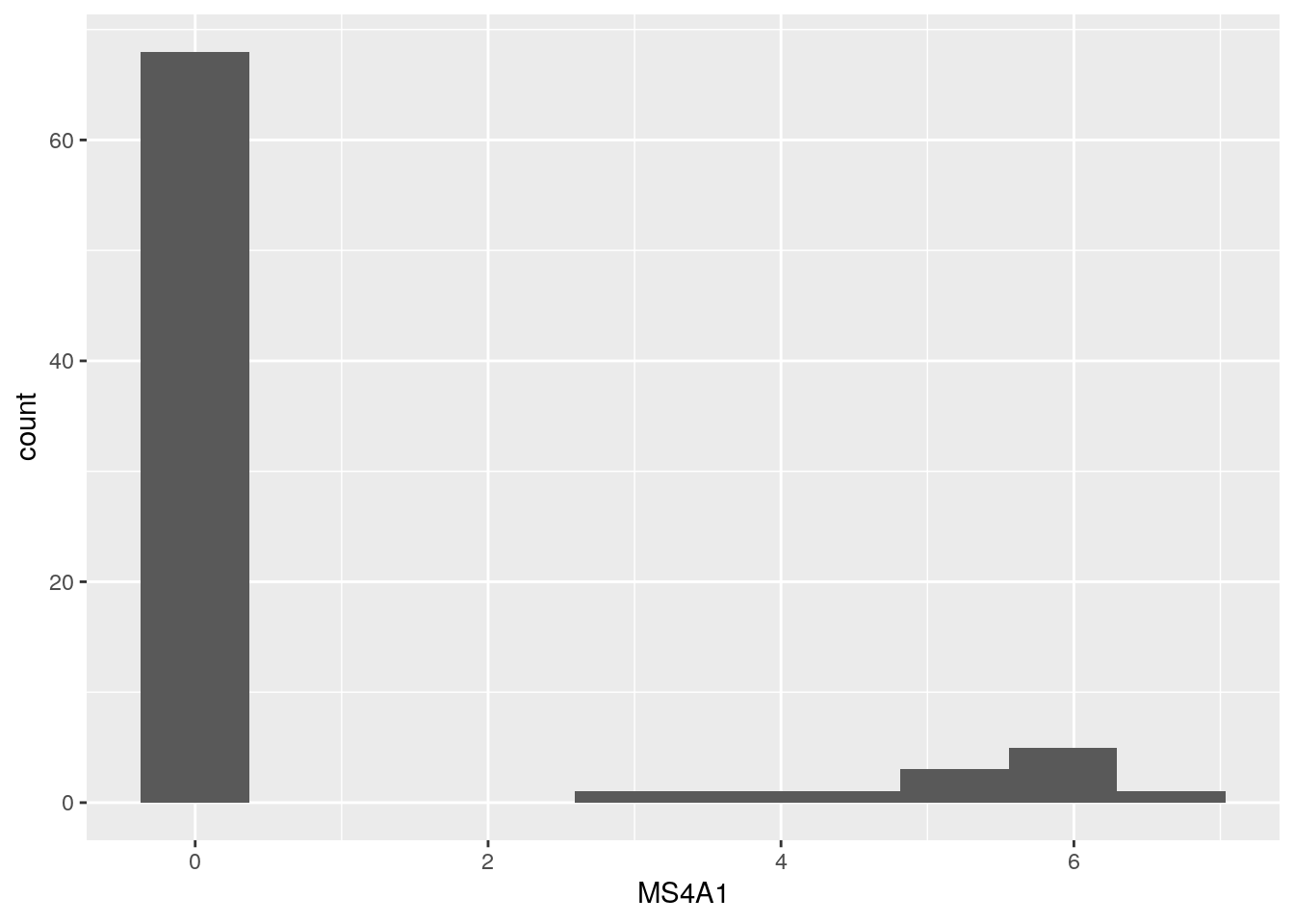
2D Plots
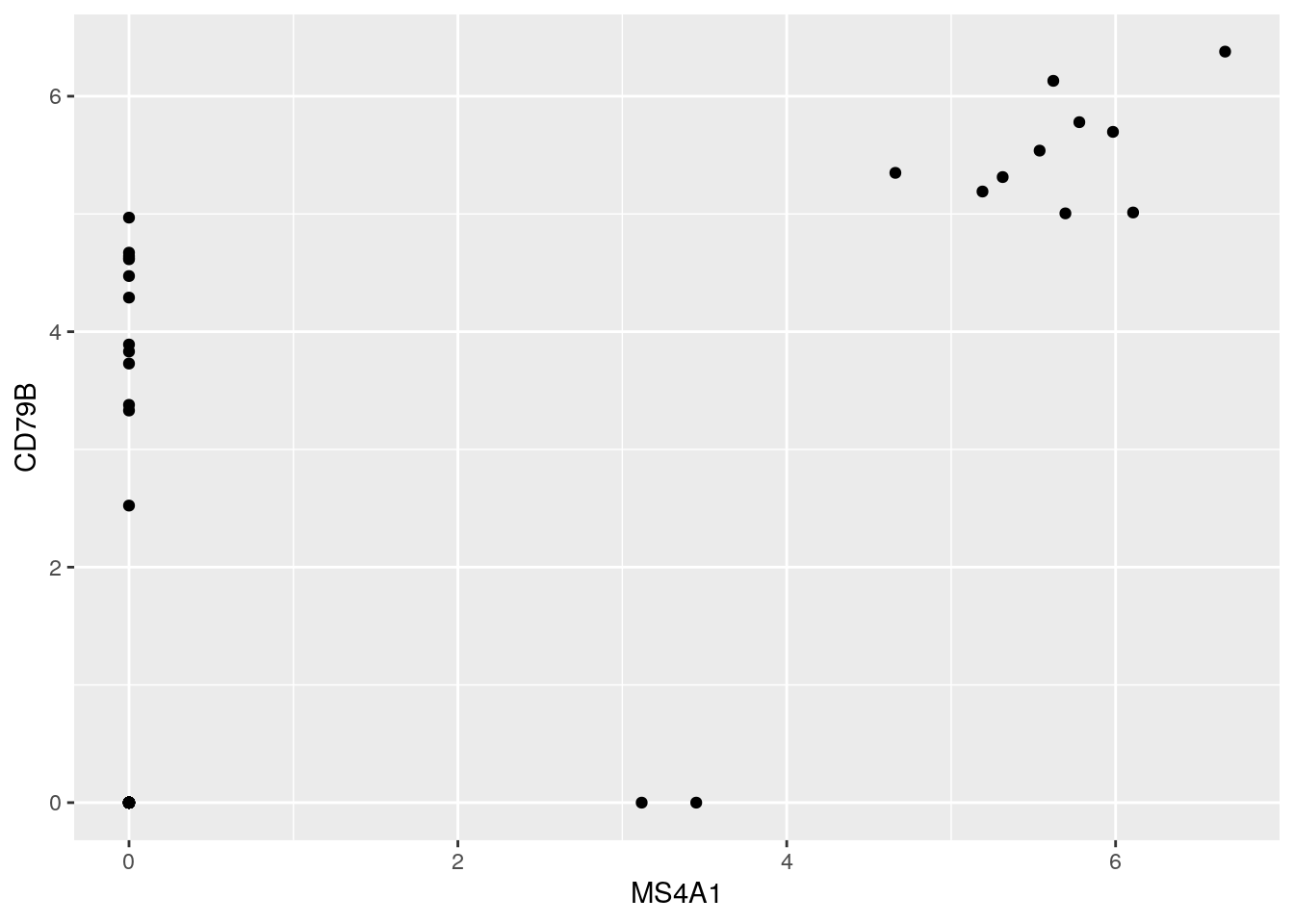
6.5.2.2 Lab B
Use different geom_ to make a different plots - try _bar_abline() - try _bin2d()
- Adding Statisitics in 2D plots
- Regression line (lm - linear model using OLS regression)
## `geom_smooth()` using formula 'y ~ x'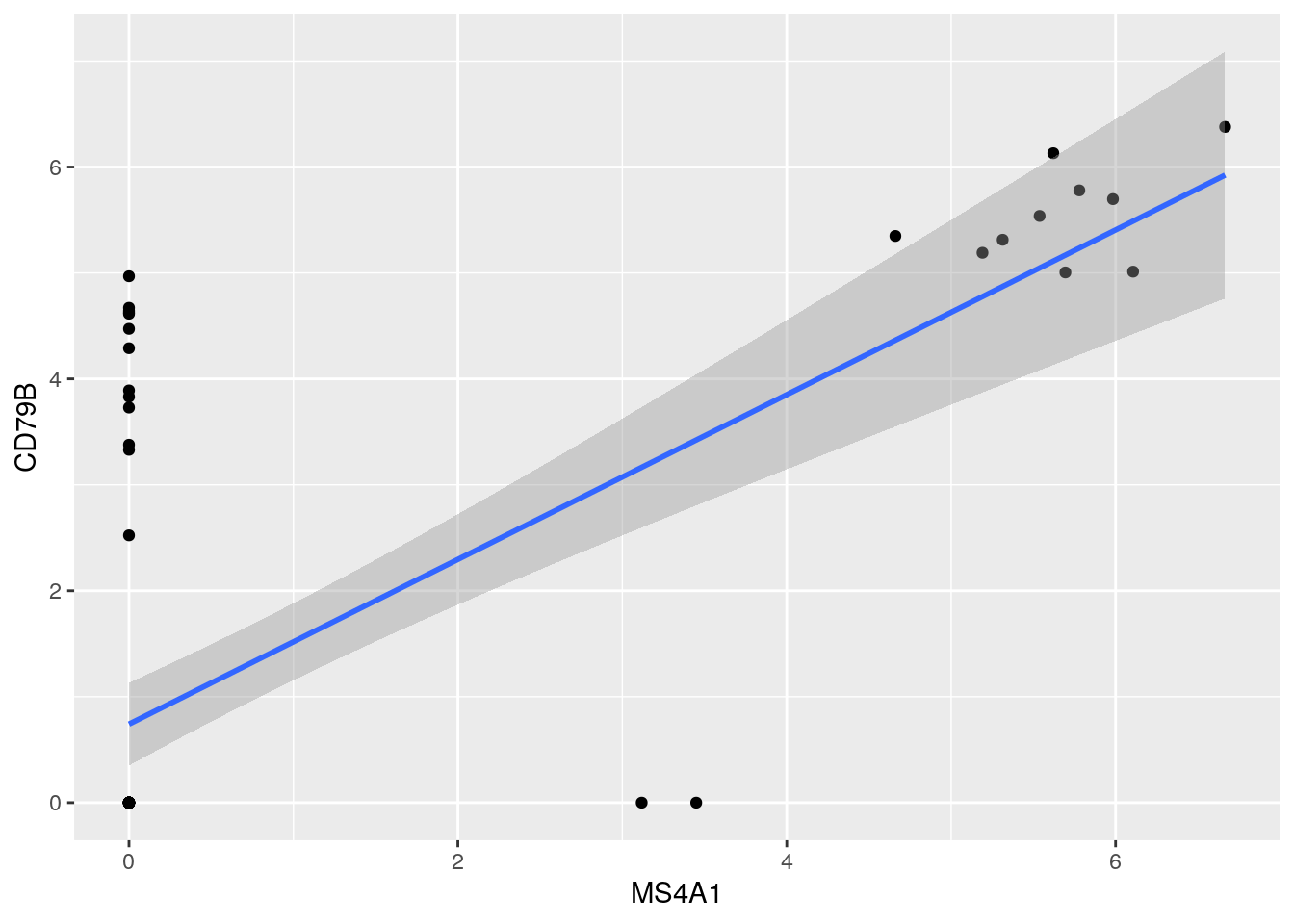
- Adding Text Labels
## notice plus `+` at the end of each line, adding a new layer!
ggplot(gbm, aes(MS4A1, CD79B)) + ## Data layer
geom_point() + ## Geometry layer
stat_smooth(method = "lm") + ##
geom_text(aes(label = rownames(gbm)))## `geom_smooth()` using formula 'y ~ x'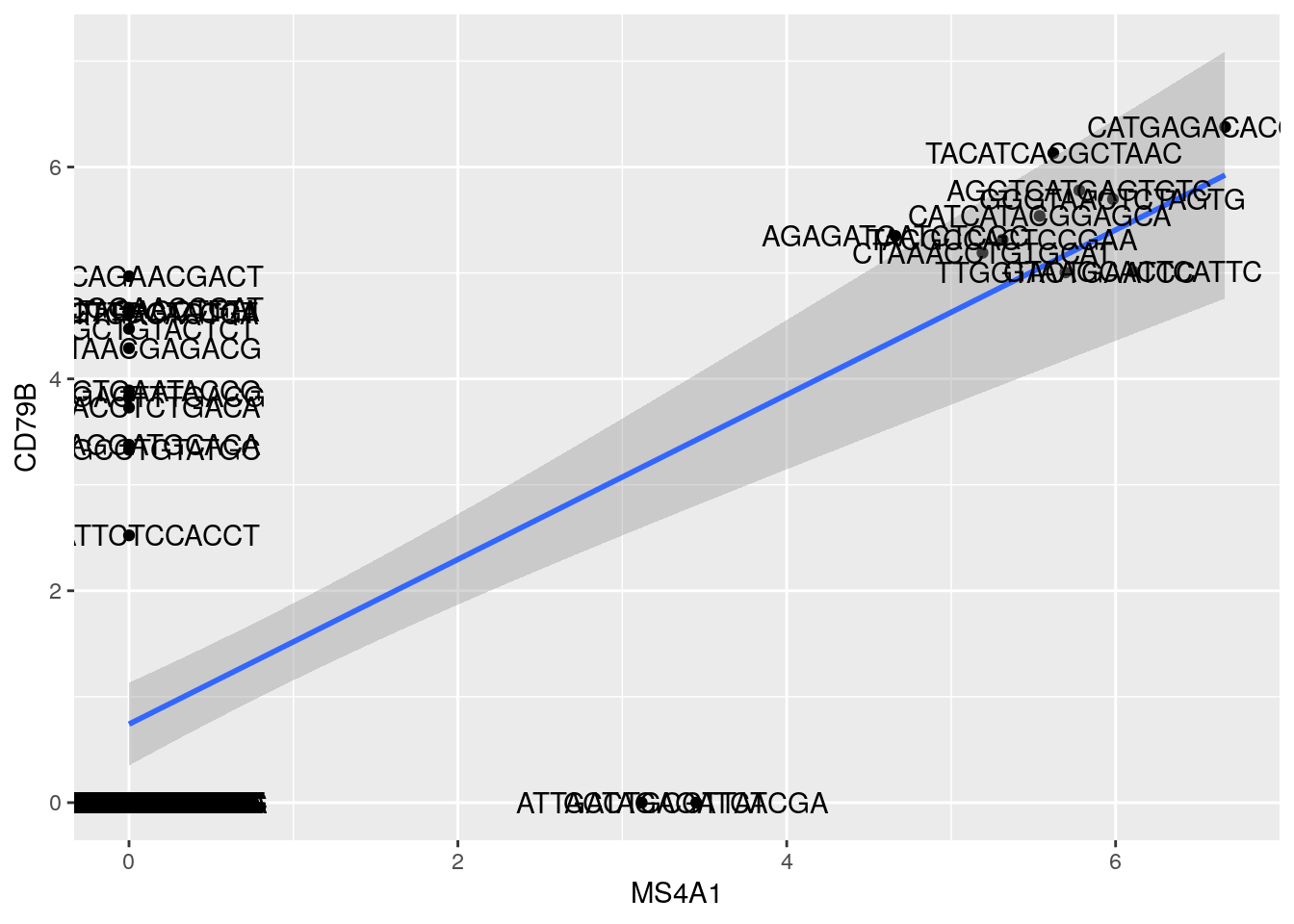
6.5.2.3 Lab C
Play arund with ggplot2. See what geoms to add and layers to include.