Smart-seq2 Single Sample Overview
9/12/2014
We are deprecating the Smart-seq2 Single Sample Pipeline. Although the code will continue to be available, we are no longer supporting it. For an alternative, see the Smart-seq2 Single Nucleus Multi Sample workflow.
| Pipeline Version | Date Updated | Documentation Author | Questions or Feedback |
|---|---|---|---|
| smartseq2_v5.1.20 | February, 2024 | Elizabeth Kiernan | Please file an issue in WARP. |
Introduction to the Smart-seq2 Single Sample Pipeline
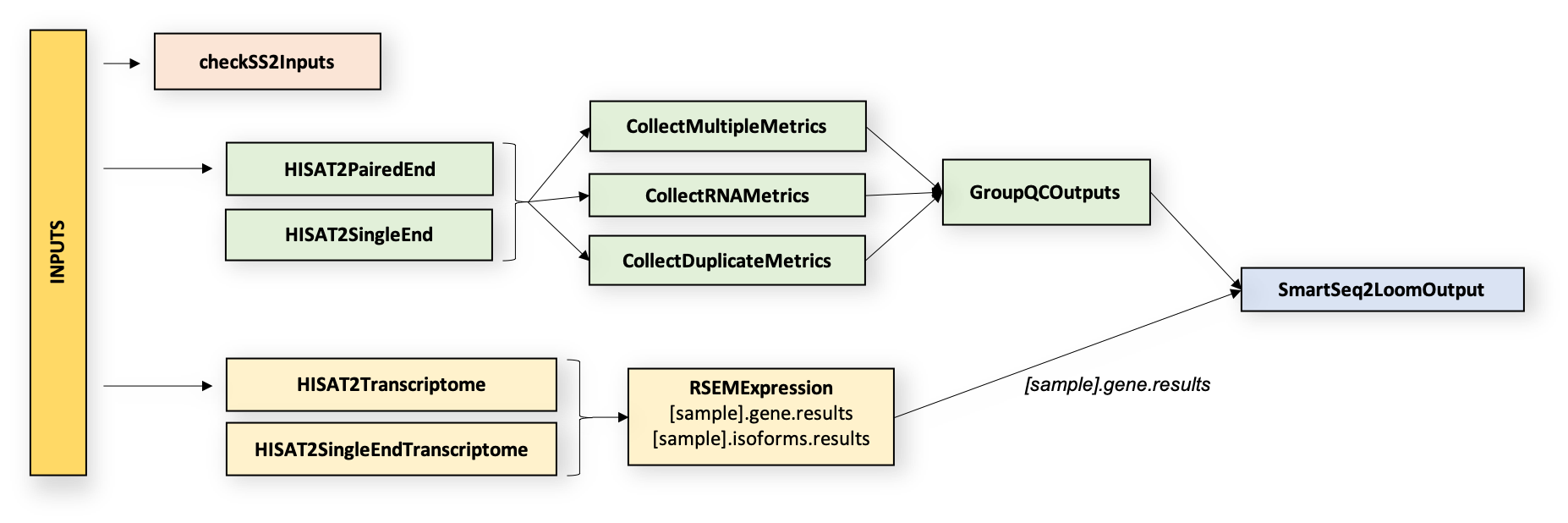
The Smart-seq2 Single Sample Pipeline (SS2) is designed by the Data Coordination Platform of the Human Cell Atlas to process single-cell RNAseq (scRNAseq) data generated by Smart-seq2 assays. The pipeline's workflow is written in WDL, is freely available on GitHub, and can be run by any compliant WDL runner (e.g. Crowmell). The pipeline is designed to process scRNA-seq data from an individual cell (to process multiple cells, see the Smart-seq2_Multi Sample pipeline).
The SS2 workflow is divided into two parts which run in parallel. In part one, the workflow aligns reads to the genome and performs quality control on genome-aligned BAMs. In part two, it aligns reads to the transcriptome and generates gene expression estimates from transcriptome-aligned BAMs. The pipeline returns reads and expression estimates in BAM, and read counts and QC metrics in Loom and CSV file format.
The pipeline has been validated to support human and mouse, stranded or unstranded, paired- or single-end, and plate- or fluidigm-based Smart-seq2 datasets. Read more in the validation section.
Check out the Smart-seq2 Publication Methods to get started!
Quick Start Table
| Pipeline Features | Description | Source |
|---|---|---|
| Assay Type | Smart-seq2 Single Sample | Smart-seq2 |
| Overall Workflow | Quality control and transcriptome quantification | Code available from GitHub |
| Workflow Language | WDL | openWDL |
| Genomic Reference Sequence (for validation) | GRCh38 human genome primary sequence and M21 (GRCm38.p6) mouse genome primary sequence | GENCODE human reference files and mouse reference files |
| Transcriptomic Reference Annotation (for validation) | V27 GENCODE human transcriptome and M21 mouse transcriptome | GENCODE human GTF and mouse GTF |
| Aligner | HISAT2 (v.2.1.0) | Kim, et al.,2019 |
| QC Metrics | Picard (v.2.26.10) | Broad Institute |
| Transcript Quantification | Utilities for processing large-scale single cell datasets | RSEM v.1.3.0 |
| Data Input File Format | File format in which sequencing data is provided | FASTQ |
| Data Output File Formats | File formats in which Smart-seq2 output is provided | BAM, Loom (generated with Loompy v.3.0.6), CSV (QC metrics and counts) |
Set-Up
Smart-seq2 Single Sample Installation and Requirements
The SS2 workflow code can be downloaded by cloning the GitHub WARP repository. For the latest release of Smart-seq2, please see the Smart-seq2 Single Sample changelog.
The workflow is deployed using Cromwell, a GA4GH compliant, flexible workflow management system that supports multiple computing platforms.
You can run the Smart-seq2 Multi-Sample workflow (a wrapper for the Single Sample workflow described in this document) in Terra, a cloud-based analysis platform. The Terra Smart-seq2 public workspace is preloaded with the Smart-seq2 workflow, example testing data, and all the required reference data.
Inputs
There are two example configuration (JSON) files available to test the SS2 workflow.
- human_single_example.json: Configurations for an example single-end human dataset
- mouse_paired_example.json: Configurations for an example mouse paired-end dataset
Sample Data Input
The pipeline is designed for both single- and paired-end reads in the form of FASTQ files. The workflow accepts two FASTQ files for paired-end experiments and one FASTQ file single-end experiments. It processes one sample (cell).
fastq1: forward reads for sample with paired-end sequencing (or reads for sample with single-end sequencing)fastq2: reverse reads for sample with paired-end sequencing (not applicable for samples with single-end sequencing)
The workflow will use modified tasks depending if a sample is paired-end or single-end. This is designated with a boolean, as detailed in the following Reference Inputs section.
Additional Reference Inputs
The Smart-seq2 Single Sample workflow requires multiple reference indexes. Information on how these indexes are created is found in the BuildIndices workflow overview documentation. The table below describes the references and each tool that uses the reference as input, when applicable.
| Workflow Step | Reference name | Reference Description | Tool |
|---|---|---|---|
| All | input_id | String containing unique identifier or name for the cell. It can be a human-readable descriptor (i.e. "cell1") or a UUID | NA |
| All | input_name | Optional string that can be used as a name/identifier for the cell | NA |
| All | output_name | Output name, can include path | NA |
| All | paired_end | A boolean describing if sample is paired-end | NA |
| All | input_id_metadata_field | Optional string that describes, when applicable, the metadata field used for input_id | NA |
| All | input_name_metadata_field | Optional string that describes, when applicable, the metadata field used for the input_name | NA |
| Genomic alignment with HISAT2 | hisat2_ref_index | HISAT2 reference index file in tarball | HISAT2 |
| hisat2_ref_name | HISAT2 reference index name | HISAT2 | |
| Picard-generated quality control metrics | genome_ref_fasta | Genome reference in fasta format | Picard |
| gene_ref_flat | RefFlat file containing the location of RNA transcripts, exon start sites, etc. | Picard | |
| rrna_intervals | Ribosomal RNA intervals file | Picard | |
| stranded | Library strand information for HISAT2; example values include FR (read corresponds to transcript), RF(read corresponds to reverse complement of transcript), or NONE | Picard | |
| Transcriptomic alignment with HISAT2 | hisat2_ref_trans_index | HISAT2 transcriptome index file in tarball | HISAT2 |
| hisat2_ref_trans_name | HISAT2 transcriptome index file name | HISAT2 | |
| Gene expression quantification with RSEM | rsem_ref_index | RSEM reference index file in tarball | RSEM |
Running Smart-seq2
The SmartSeq2SingleSample.wdl is in the pipelines/smartseq2_single_sample folder of the WARP repository and implements the workflow by importing individual tasks (written in WDL script) from the WARP tasks folder.
Smart-seq2 Workflow Summary
Overall, the workflow is divided into two parts that are completed after an initial input validation step. Each workflow part comprises tasks (WDL scripts) that are summarized below and are available in the WARP tasks folder in GitHub.
Part 1: Quality Control Tasks
- Aligns reads to the genome with HISAT2 v.2.1.0
- Calculates summary metrics from an aligned BAM using Picard v.2.26.10
Part 2: Transcriptome Quantification Tasks
- Aligns reads to the transcriptome with HISAT v.2.1.0
- Quantifies gene expression using RSEM v.1.3.0
The table below provides links to each of the Smart-seq2 Single Sample pipeline's task WDL scripts, as well as documentation for each task's software tools.
If you are looking for the parameters used for each task/tool, click on the task link in the table below and see the command {} section of the task WDL. The task's Docker image is also specified in the task WDL in the # runtime values section as String docker =.
Part 1: Quality Control Tasks
1.1 Align reads to the genome using HISAT2
HISAT2 is a fast, cost-efficient alignment tool that can determine the presence of non-transcript sequences and true transcript sequences, taking into account the presence of single-nucleotide polymorphisms (Kim et al.,2019). The Smart-seq2 Single Sample workflow uses the HISAT2 task to call HISAT2 and perform graph-based alignment of paired- or single-end reads (in the form of FASTQ files) to a reference genome. This task requires a reference index which can be built using the BuildIndices.wdl documentation. The outputs of the task include a genome-aligned BAM file, a BAM index, and an alignment log file.
1.2 Calculate summary metrics using Picard
Picard is a suite of command line tools used for manipulating high-throughput sequencing data. The Picard task uses Picard tools to calculate quality control measurements on the HISAT2 genome-aligned BAM file. The task requires a reference genome fasta, a RefFlat gene annotation file, and an RNA intervals file (see the BuildIndices workflow for creating references). The outputs of the task are text and PDF files for each metric.
The Picard task generates QC metrics by using three sub-tasks:
CollectMultipleMetrics: calls the CollectMultipleMetrics tool which uses the aligned BAM file and reference genome fasta to collect metrics on alignment, insert size, GC bias, base distribution by cycle, quality score distribution, quality distribution by cycle, sequencing artifacts, and quality yield.
CollectRnaMetrics: calls the CollectRnaSeqMetrics tool which uses the aligned BAM, a RefFlat genome annotation file, and a ribosomal intervals file to produce RNA alignment metrics (metric descriptions are found in the Picard Metrics Dictionary).
CollectDuplicationMetrics: calls the MarkDuplicates tool which uses the aligned BAM to identify duplicate reads (output metrics are listed in the Picard Metrics Dictionary).
Part 2: Transcriptome Quantification Tasks
2.1 Align reads to the transcriptome using HISAT2
The HISAT2.HISAT2RSEM task uses HISAT2 to align reads to the reference transcriptome. The task requires the hisat2_ref_trans_index file and the sample FASTQ files as input. The output of this task is a transcriptome-aligned BAM file and an alignment log file.
2.2 Quantify gene expression using RSEM
RSEM is a software package for quantifying transcript abundances (Li and Dewey, 2011). The Smart-seq2 Single Sample workflow uses the RSEM.RSEMExpression task to calculate expression estimates from a transcriptome-aligned BAM file using the rsem_ref_index file for reference input. The RSEM tool rsem-calculate-expression is used to estimate gene/isoform expression.
The RSEM task returns the following output files:
- rsem_gene: gene level expression estimates in FPKM, TPM, and counts ("expected_count")
- rsem_isoform: isoform level expression estimates in FPKM, TPM, and counts ("expected_count")
- rsem_time: the time consumed by aligning reads
- rsem_cnt: alignment statistics
- rsem_model: RNA-seq model parameters
- rsem_theta: fraction of reads resulting from background
Only the rsem_gene (TPM and expected_count), rsem_isoform (TPM and expected_count), and rsem_cnt files are used for the final outputs of the Smart-seq2 Single Sample workflow.
After the Smart-seq2 workflow generates HISAT2, Picard and RSEM metrics, the GroupMetricsOutputs task combines most metrics into a "group_results" CSV file array. The workflow uses this array in downstream Loom file generation. The following HISAT2, Picard and RSEM outputs are inputs for this task:
- HISAT2_log_file
- base_call_dist_metrics
- gc_bias_detail_metrics
- pre_adapter_details_metrics
- pre_adapter_summary_metrics
- bait_bias_detail_metrics
- error_summary_metrics
- alignment_summary_metrics
- dedup_metrics
- rna_metrics
- gc_bias_summary_metrics
- HISAT2RSEM_log_file
- RSEMExpression.rsem_cnt
Outputs
The table below details the final outputs of the SS2 workflow.
| Output Name | Output Description | Output Format |
|---|---|---|
| Pipeline version | Version of the processing pipeline run on this data | string |
| aligned_bam | HISAT2 out BAM | BAM |
| bam_index | HISAT2 BAM index | BAM |
| insert_size_metrics | Picard insert size metrics | txt |
| quality_distribution_metrics | Picard quality distribution metrics | txt |
| quality_by_cycle_metrics | Picard quality by cycle metrics | txt |
| bait_bias_summary_metrics | Picard bait bias summary metrics | txt |
| rna_metrics | Picard RNA metrics | txt |
| group_results | Array of Picard metric files generated by the GroupQCOutputs task | CSV |
| rsem_gene_results | RSEM file containing gene-level expression estimates | tab-delimited |
| rsem_isoform_results | RSEM file containing isoform-level expression estimates | tab delimited |
| loom_output_files | Loom file containing RSEM TPM and expected_counts and metrics | Loom |
The final count matrix is in Loom format and includes only the group_results CSV files and the rsem_gene_results (TPM and expected_count). Note that the TPMs are contained in the Loom “matrix", whereas expected_count is contained in the “layers/estimated_counts".
Please note that we have deprecated the previously used Zarr array output. The pipeline now uses the Loom file format as the default output.
Validation
The SS2 pipeline has been validated for processing human and mouse, stranded or unstranded, paired- or single-end, and plate- or fluidigm-based Smart-seq2 datasets (see links to validation reports in the table below).
| Workflow Configuration | Link to Report |
|---|---|
| Mouse paired-end | Report |
| Human and mouse single-end | Report |
| Human stranded fluidigm | Report |
Versioning
All SS2 release notes are documented in the Smartseq2 Single Sample changelog.
Citing the Smart-seq2 Single Sample Pipeline
If you use the Smart-seq2 Single Sample Pipeline in your research, please identify the pipeline in your methods section using the Smart-seq2 Single Sample SciCrunch resource identifier.
- Ex: Smart-seq2 Single Sample Pipeline (RRID:SCR_021228)
Please also consider citing our preprint:
Degatano, K., Awdeh, A., Cox III, R.S., Dingman, W., Grant, G., Khajouei, F., Kiernan, E., Konwar, K., Mathews, K.L., Palis, K., et al. Warp Analysis Research Pipelines: Cloud-optimized workflows for biological data processing and reproducible analysis. Bioinformatics 2025; btaf494. https://doi.org/10.1093/bioinformatics/btaf494
Consortia Support
This pipeline is supported and used by the Human Cell Atlas (HCA) project.
If your organization also uses this pipeline, we would love to list you! Please filing an issue in WARP.
Have Suggestions?
Please help us make our tools better by filing an issue in WARP; we welcome pipeline-related suggestions or questions.