Welcome to WARP
The Warp Analysis Research Pipelines repository is a collection of cloud-optimized pipelines for processing biological data from the Broad Institute Data Sciences Platform and collaborators.
The contents of this repository are open source and released under the BSD 3-Clause license.
WARP Philosophy
Our mission is to develop production-grade, cloud-optimized pipelines that serve the needs of large-scale research consortia and the broader scientific community. Since many of these consortia have adopted Terra as their primary computing environment, most WARP pipelines are written in WDL and tuned for optimal performance on Terra. As community needs evolve, WARP will adapt accordingly to support those environments.
We do not position WDL as inherently superior to workflow languages like Nextflow or Snakemake. Rather, we focus on addressing the specific needs of scientific consortia and research communities that prioritize reproducibility, scalability, and seamless integration with the Terra platform.
WARP Overview
WARP pipelines provide robust, standardized data analysis for the Broad Institute Genomics Platform and large consortia like the Human Cell Atlas and the BRAIN Initiative. You can count on WARP for rigorously scientifically validated, high scale, reproducible and open source pipelines.
Our pipelines are written as “workflows” using the Workflow Description Language (WDL) and they process a broad spectrum of “omic” and array-related datasets (see the overview table below).
| Pipeline Category | Data Types |
|---|---|
| Germline Variant Discovery | Genomes, Exomes |
| Genotyping Arrays | Variant discovery, Chip validation, Joint array analysis |
| Single-cell/nuclei Transcriptomics | Droplet based (10x Genomics), Smartseq2 |
| Single-cell Epigenomics | Single nuclei ATAC-seq, Single nuclei MethylC-seq |
| Joint Genotyping | Genomes, Exomes |
| Somatic Alignment (beta) | Exomes |
Try our pipelines in Terra, a platform for collaborative cloud analysis! Learn how in the Using WARP section.
Navigating WARP
All versioned and released pipelines are in one of the three pipelines subdirectories: broad (pipelines for the Broad Institute’s Genomics Platform), cemba (pipelines for the BRAIN Initiative) or skylab (pipelines for the BRAIN Initiative and Human Cell Atlas Project).
Each pipeline directory hosts a main workflow (WDL) that includes a pipeline version number and a corresponding changelog file.
Workflows may call additional WDLs, referred to as tasks, that are located in the tasks directory.
Pipelines that are in progress or have not yet been validated are in the beta-pipelines folder.
Dockers and custom tools maintained in warp-tools repository
Each WARP workflow uses Docker images that contain the necessary software for the workflow's commands. All Docker images, build scripts for Docker images, and custom tools are maintained in a separate repository, warp-tools.
Using WARP
There are three ways to use WARP pipelines:
1. Download the workflow and run on a WDL-compatible execution engine
WDL workflows run on multiple systems, including Cromwell, miniWDL, and dxWDL (see the openwdl documentation).
To run a pipeline’s latest release, first navigate to WARP releases page, search for your pipeline’s tag, and download the pipeline’s assets (the WDL workflow, the JSON, and the ZIP with accompanying dependencies; see Optimus example below).
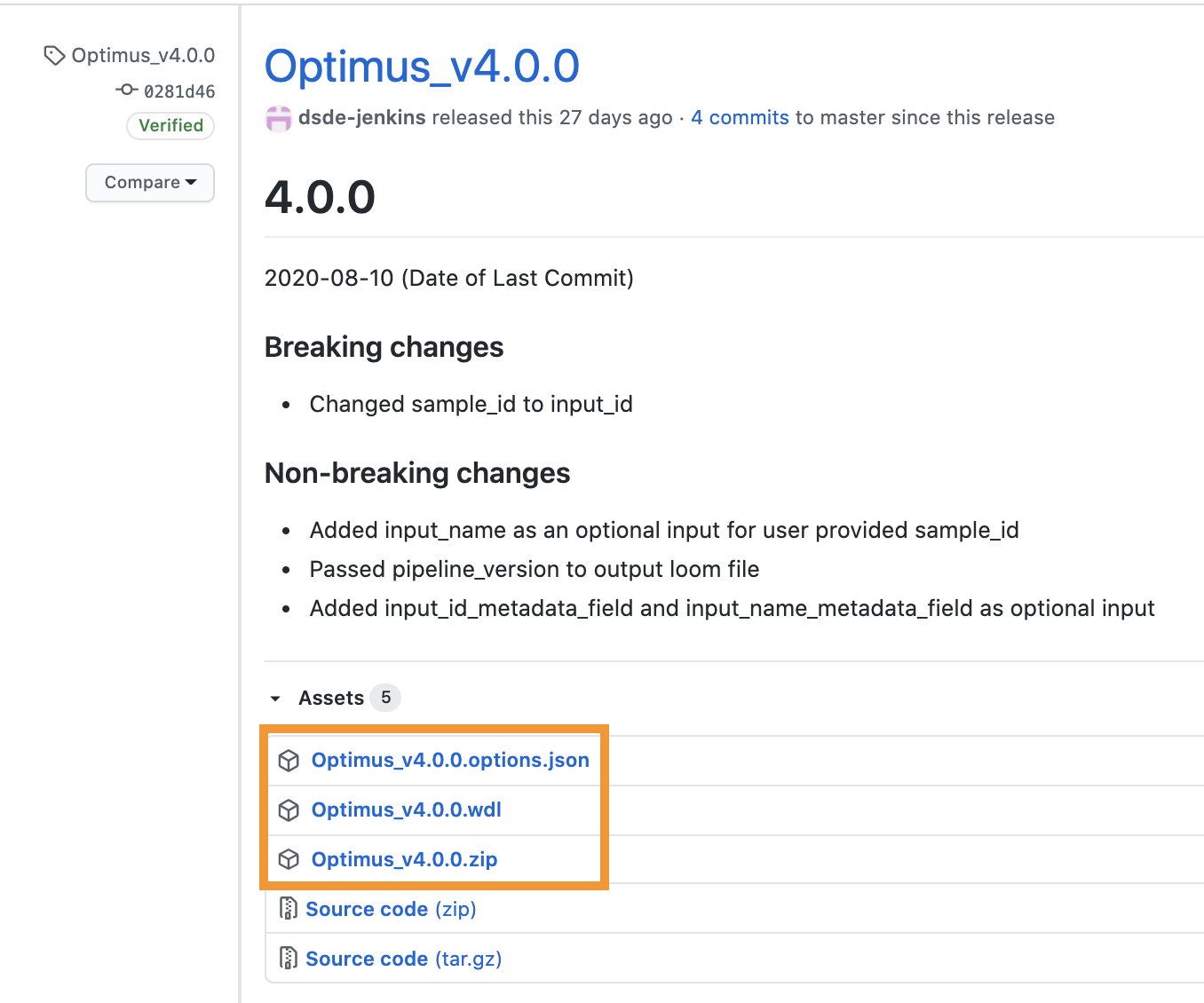
You can also discover and search releases using the WARP command-line tool Wreleaser.
After downloading the pipeline’s assets, launch the workflow following your execution engine’s instructions.
2. Run the pipeline in Terra
Several WARP pipelines are available in public workspaces on the Terra cloud platform. These workspaces include both the WDL workflow and downsampled data so that you can test the pipeline at low-cost.
If you are new to Terra, you can get started by registering with your Google account and visiting Terra Support. After registration, search for WARP-related workspaces with the “warp-pipelines” tag.

To test the pipeline, clone (make a copy of) the workspace following the instructions in this Terra Support guide.
3. Run or export the pipeline from Dockstore
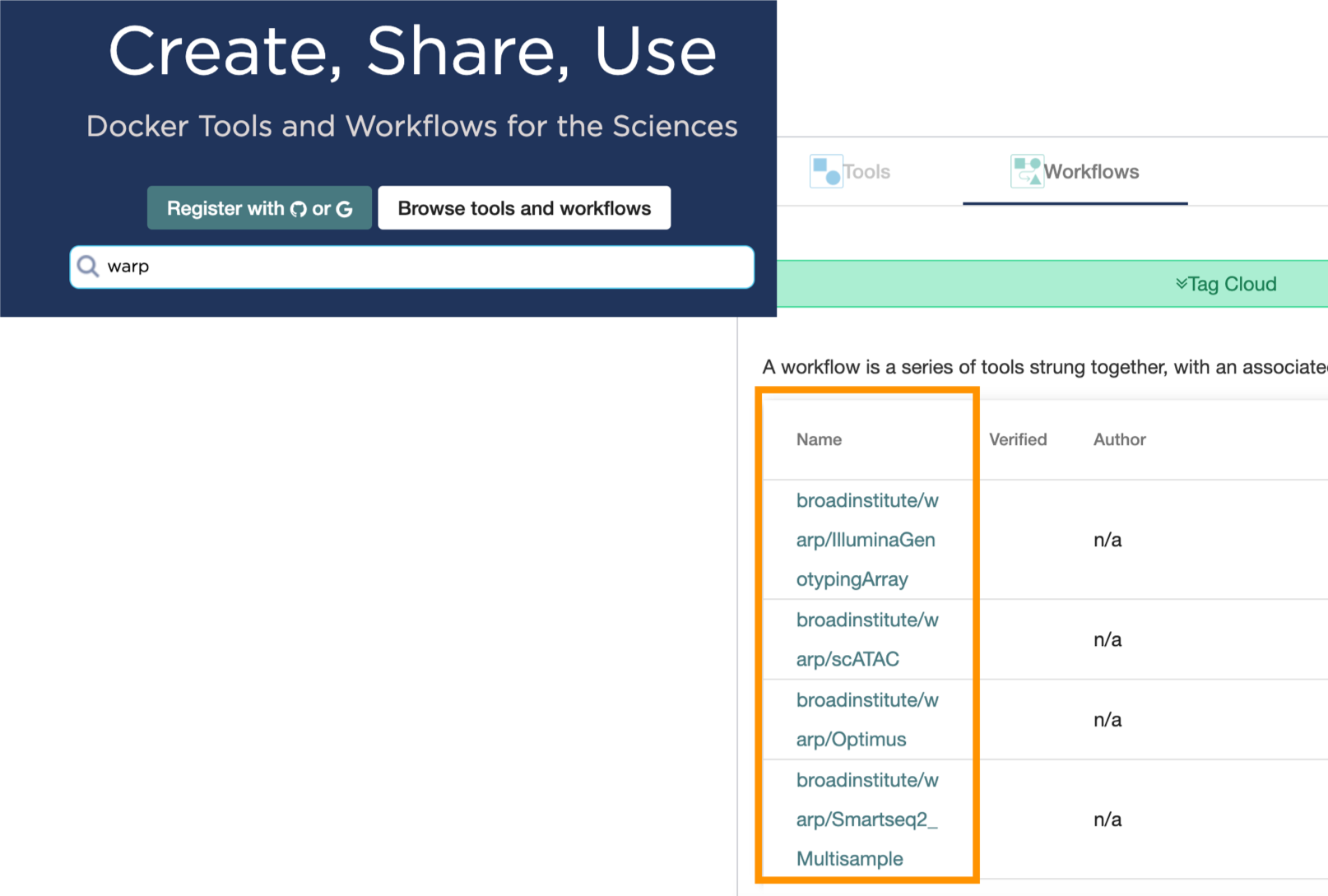
Dockstore is a GA4GH compliant open platform for sharing Docker-based tools like WDL workflows. You can find WARP pipelines in Dockstore and run them on the Dockstore platform or export them to other platforms (including Terra).
To view all available pipelines, just search “warp” in the Dockstore search and browse the workflow list. See Dockstore documentation for details on launching the workflow.
WARP Versioning and Releasing
Pipelines in WARP are versioned semantically to support reproducibility in scientific analysis and provide clearer analysis provenance. Version numbers allow researchers to confirm their data has all been processed in a compatible way. Semantic versioning gives immediate insight into the compatibility of pipeline outputs. Read more about versioning and releasing in WARP.
Testing in WARP
Each pipeline in WARP has accompanying continuous integration tests that run on each pull request (PR). These tests help ensure that no unexpected changes are made to each pipeline and confirm that each affected pipeline is tested with any changes to shared code. To support rapid development iteration, only the pipelines affected by a PR are tested and PRs to the develop branch run “plumbing” tests using small or downsampled inputs. When the staging branch is promoted to master, the updated pipelines will be tested more rigorously on a larger selection of data that covers more scientific test cases. Read more about our testing process.
Feedback
WARP is always evolving! Please file an issue in WARP with suggestions, feedback, or questions. We are always excited to discuss cloud data processing, provenance and reproducibility in scientific analysis, new pipeline features, or potential collaborations. Don’t hesitate to reach out!
Our planned upcoming improvements include:
- A unified testing infrastructure that eases the overhead for contribution
- Full contribution guidance
- Continued additions of pipeline documentation
- Pre-written methods sections and DOIs to enable easy publication citations
- More pipelines: bulk RNAseq, SlideSeq, updates to joint genotyping
Citing WARP
When citing WARP, please use the following:
Degatano, K., Awdeh, A., Cox III, R.S., Dingman, W., Grant, G., Khajouei, F., Kiernan, E., Konwar, K., Mathews, K.L., Palis, K., et al. Warp Analysis Research Pipelines: Cloud-optimized workflows for biological data processing and reproducible analysis. Bioinformatics 2025; btaf494. https://doi.org/10.1093/bioinformatics/btaf494
Acknowledgements
WARP is maintained by the Broad Institute Data Sciences Platform (DSP) in collaboration with partner organizations. The Lantern Pipelines team maintains the repository with invaluable scientific oversight and pipeline contributions from the DSP Methods group as well as the HCA and BRAIN Initiative Analysis Working Groups. We thank the DSP Customer Delivery team for their help with user-, documentation-, and Terra- support. WARP pipelines have been made in collaboration with or informed by scientists across many institutions, including: labs at the Broad Institute, the European Bioinformatics Institute, Chan Zuckerburg Initiative, NY Genome Center, University of California Santa Cruz, Berkeley, and San Diego, the Allen Institute, Johns Hopkins Medical Institute, and the Baylor College of Medicine.