6 Feature Selection and Cluster Analysis
6.1 Abstract
Many methods have been used to determine differential gene expression from single-cell RNA (scRNA)-seq data. We evaluated 36 approaches using experimental and synthetic data and found considerable differences in the number and characteristics of the genes that are called differentially expressed. Prefiltering of lowly expressed genes has important effects, particularly for some of the methods developed for bulk RNA-seq data analysis. However, we found that bulk RNA-seq analysis methods do not generally perform worse than those developed specifically for scRNA-seq. We also present conquer, a repository of consistently processed, analysis-ready public scRNA-seq data sets that is aimed at simplifying method evaluation and reanalysis of published results. Each data set provides abundance estimates for both genes and transcripts, as well as quality control and exploratory analysis reports. (???)
Cells are the basic building blocks of organisms and each cell is unique. Single-cell RNA sequencing has emerged as an indispensable tool to dissect the cellular heterogeneity and decompose tissues into cell types and/or cell states, which offers enormous potential for de novo discovery. Single-cell transcriptomic atlases provide unprecedented resolution to reveal complex cellular events and deepen our understanding of biological systems. In this review, we summarize and compare single-cell RNA sequencing technologies, that were developed since 2009, to facilitate a well-informed choice of method. The applications of these methods in different biological contexts are also discussed. We anticipate an ever-increasing role of single-cell RNA sequencing in biology with further improvement in providing spatial information and coupling to other cellular modalities. In the future, such biological findings will greatly benefit medical research. (???)
6.2 Seurat Tutorial Redo
For this tutorial, we will be analyzing the a dataset of Peripheral Blood Mononuclear Cells (PBMC) freely available from 10X Genomics. There are 2,700 single cells that were sequenced on the Illumina NextSeq 500. The raw data can be found here.
mkdir /home/genomics/workshop_materials/scrna/pbmc3k
wget https://s3-us-west-2.amazonaws.com/10x.files/samples/cell/pbmc3k/pbmc3k_filtered_gene_bc_matrices.tar.gz -O /home/genomics/workshop_materials/scrna/pbmc3k/pbmc3k_filtered_gene_bc_matrices.tar.gz && \
cd /home/genomics/workshop_materials/scrna/pbmc3k/ && \
tar -xzf pbmc3k_filtered_gene_bc_matrices.tar.gzTask: Check the dirname to directory where you saved your data
knitr::opts_knit$set(progress=FALSE, verbose=FALSE)
library(Seurat)
library(dplyr)
library(ggplot2)
library(CountClust)
##dirname <- "/home/genomics/workshop_materials/scrna/"
dirname <- "/Users/kgosik/Documents/data/cellranger/"
counts_matrix_filename = paste0(dirname, "pbmc3k/filtered_gene_bc_matrices/hg19/")
counts <- Read10X(data.dir = counts_matrix_filename) # Seurat function to read in 10x count data### seurat<-CreateSeuratObject(raw.data = counts, ? = 3, ? = 350, project = "10X_NSCLC")
seurat <- CreateSeuratObject(counts = counts, min.cells = 3, min.features = 350, project = "10X_PBMC")## Warning: Feature names cannot have underscores ('_'), replacing
## with dashes ('-')6.2.1 Preprocessing Steps
This was all covered in the last Lab!
# The number of genes and UMIs (nFeature_RNA nCount_RNA) are automatically calculated
# for every object by Seurat. For non-UMI data, nCount_RNA represents the sum of
# the non-normalized values within a cell We calculate the percentage of
# mitochondrial genes here and store it in percent.mito using AddMetaData.
# We use object@raw.data since this represents non-transformed and
# non-log-normalized counts The % of UMI mapping to MT-genes is a common
# scRNA-seq QC metric.
seurat[["percent.mt"]] <- PercentageFeatureSet(object = seurat, pattern = "^MT-")
##VlnPlot(object = seurat, features = c("nFeature_RNA", "nCount_RNA", "percent.mt"), ncol = 3)# FeatureScatter is typically used to visualize gene-gene relationships, but can
# be used for anything calculated by the object, i.e. columns in
# object@meta.data, PC scores etc. Since there is a rare subset of cells
# with an outlier level of high mitochondrial percentage and also low UMI
# content, we filter these as well
par(mfrow = c(1, 2))
FeatureScatter(object = seurat, feature1 = "nCount_RNA", feature2 = "percent.mt")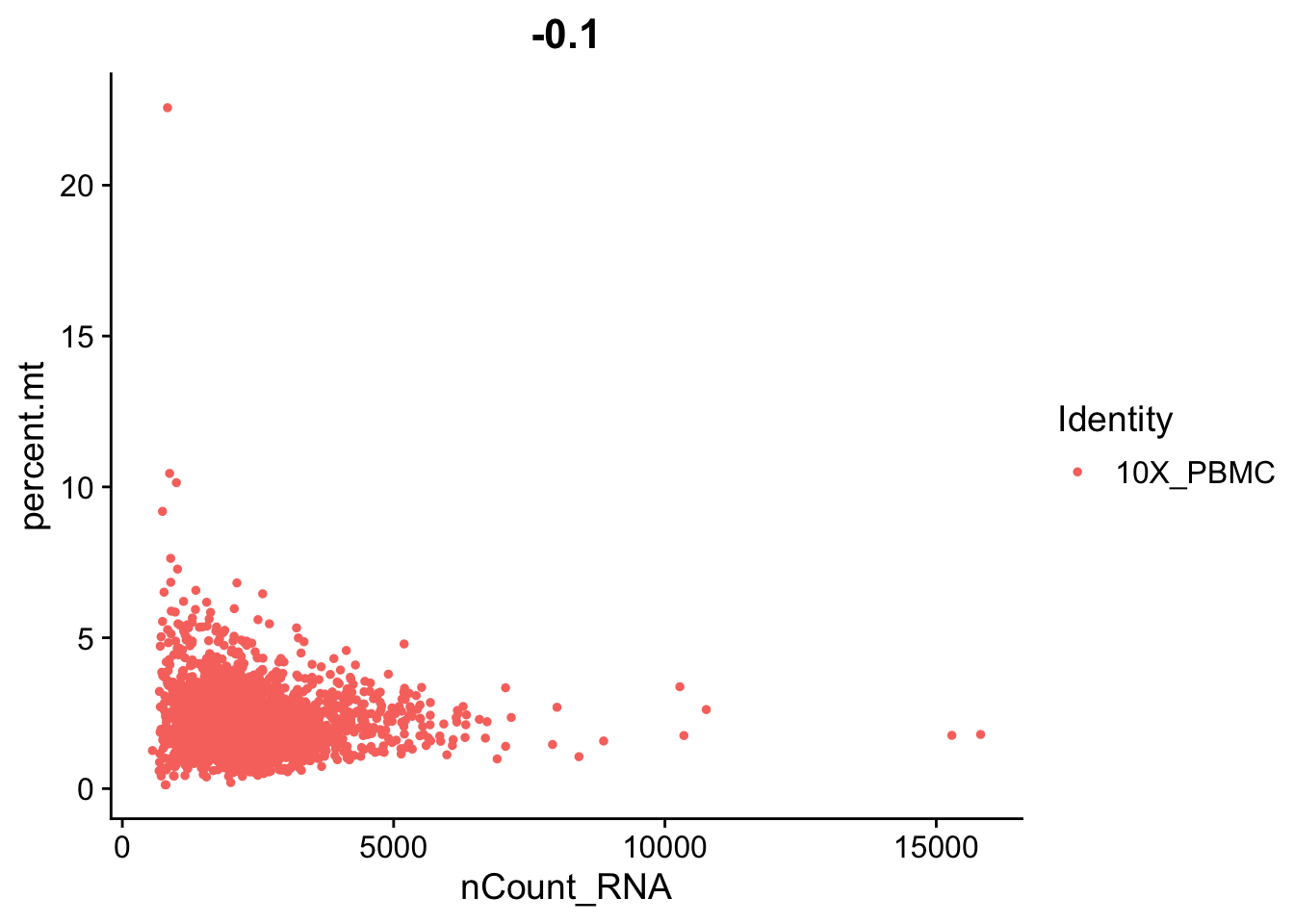
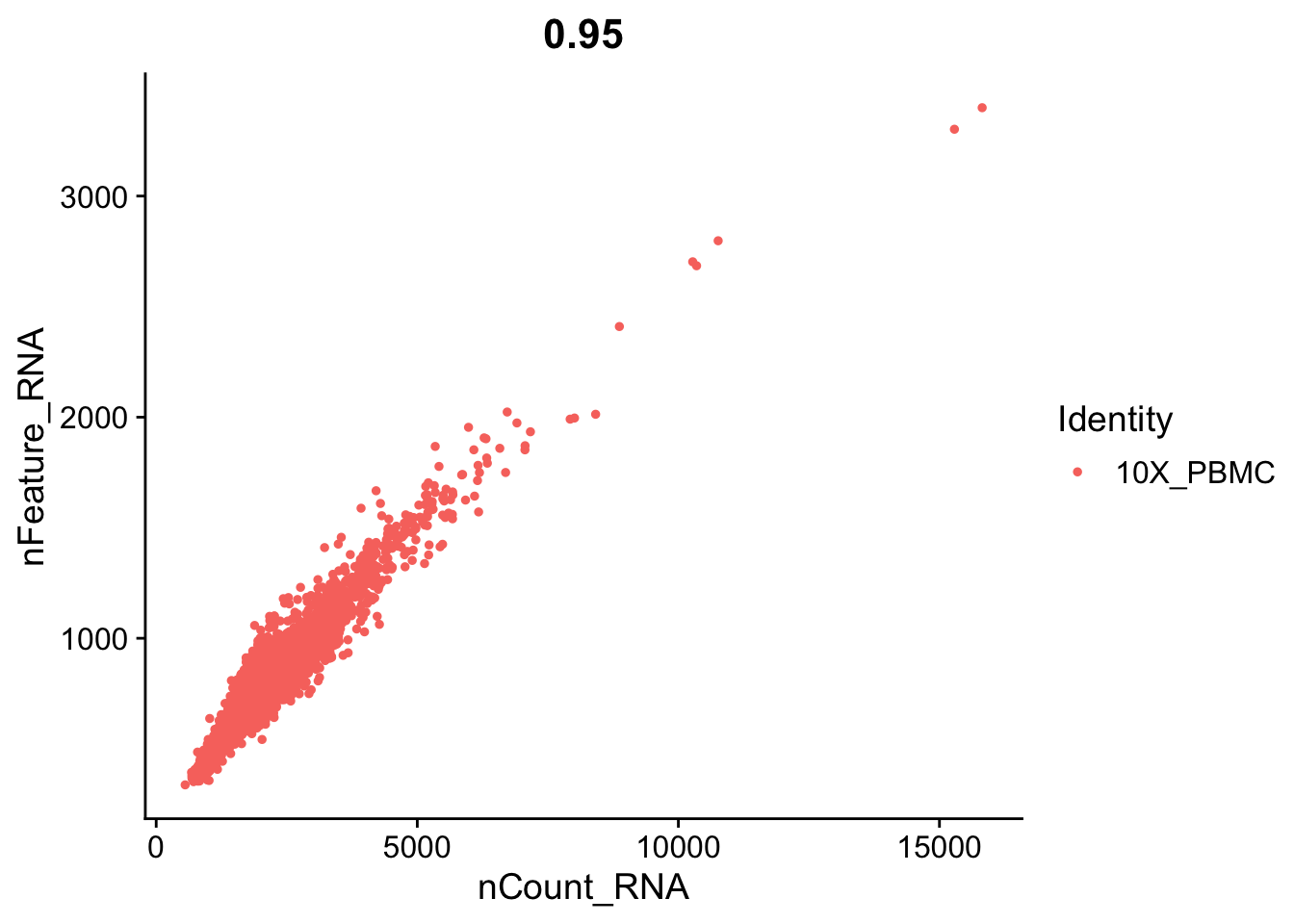
# We filter out cells that have unique gene counts over 2,500 or less than
# 200 Note that low.thresholds and high.thresholds are used to define a
# 'gate'. -Inf and Inf should be used if you don't want a lower or upper
# threshold.
# seurat <- SubsetData(object = seurat,
# subset.names = c("nFeature_RNA", "percent.mt"),
# low.thresholds = c(200, -Inf),
# high.thresholds = c(2500, 0.1))
seurat <- subset(seurat, nFeature_RNA < 2500)
seurat <- subset(seurat, nFeature_RNA > 200)
seuart <- subset(seurat, percent.mt < 10)seurat <- NormalizeData(object = seurat, normalization.method = "LogNormalize", scale.factor = 10000)# Read in a list of cell cycle markers, from Tirosh et al, 2015.
# We can segregate this list into markers of G2/M phase and markers of S phase.
s.genes <- Seurat::cc.genes$s.genes
s.genes <- s.genes[s.genes %in% rownames(seurat)] # genes in dataset
g2m.genes <- Seurat::cc.genes$g2m.genes
g2m.genes <- g2m.genes[g2m.genes %in% rownames(seurat)] # genes in dataset
seurat <- CellCycleScoring(object = seurat, s.features = s.genes, g2m.features = g2m.genes, set.ident = TRUE)6.2.2 Start of Identifying Cell Types
6.2.2.1 Scaling
This part is where you mean center the data, substract the mean. You also divide by the standard deviation to make everything to a ‘standard normal’, where the mean is zero and the standard deviation is 1.
## Regressing out batch, percent.mt## Centering and scaling data matrixTask: Try Regressing Other Variables
## randomly making a batch id data.frame
batch_ids <- data.frame(barcode = rownames(seurat@meta.data),
batch_id = sample(0:2, NROW(seurat@meta.data), replace = TRUE),
stringsAsFactors = FALSE)
row.names(batch_ids) <- row.names(seurat@meta.data)
seurat <- AddMetaData(object = seurat, metadata = batch_ids, col.name = NULL)
seurat <- ScaleData(object = seurat, vars.to.regress = 'batch_id')6.2.2.2 Perform linear dimensional reduction (PCA)
This will run pca on the
seurat <- RunPCA(object = seurat,
# features = seurat@assays$RNA@var.features,
ndims.print = 1:5,
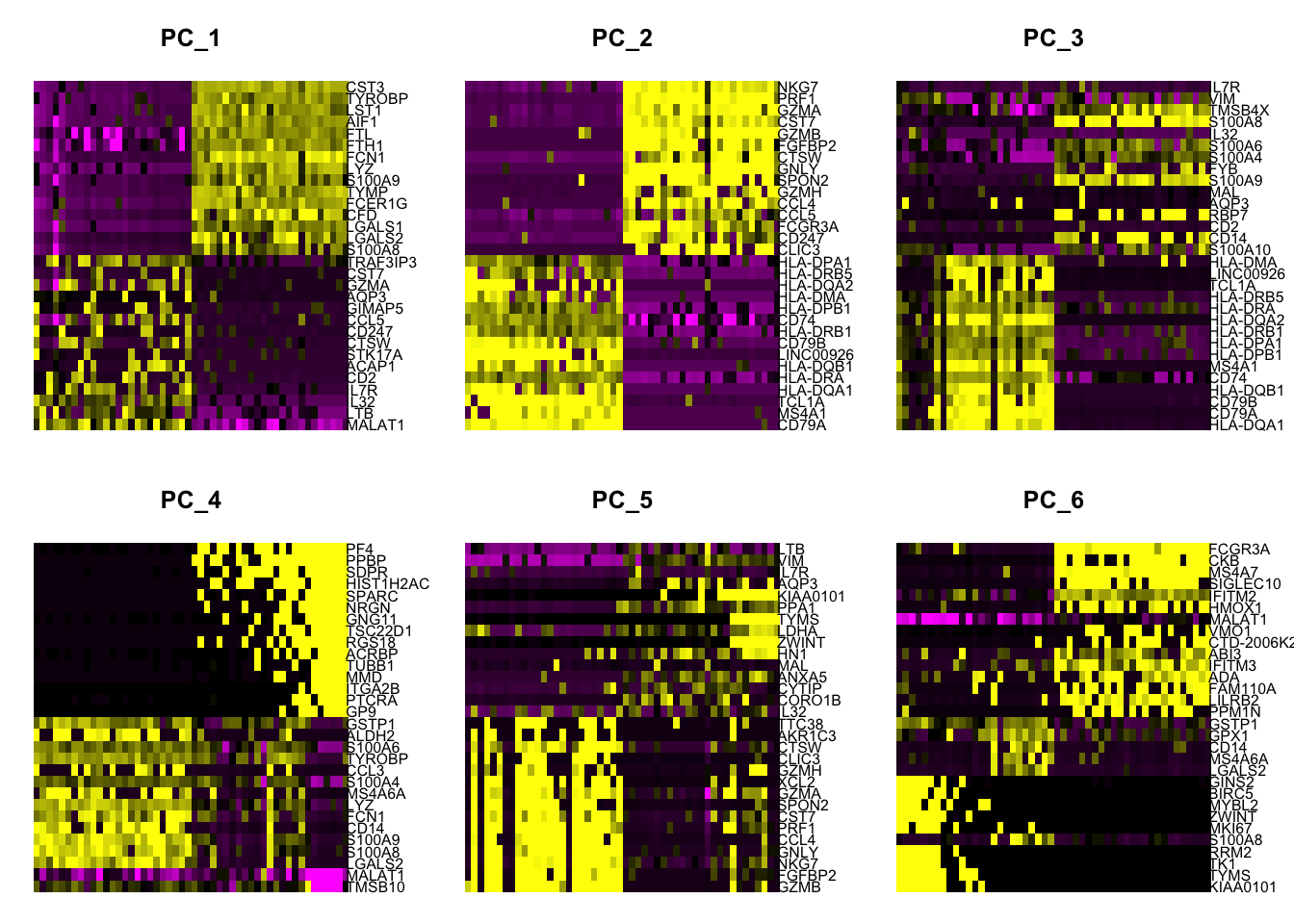
nfeatures.print = 5)## PC_ 1
## Positive: MALAT1, LTB, IL32, IL7R, CD2
## Negative: CST3, TYROBP, LST1, AIF1, FTL
## PC_ 2
## Positive: CD79A, MS4A1, TCL1A, HLA-DQA1, HLA-DRA
## Negative: NKG7, PRF1, GZMA, CST7, GZMB
## PC_ 3
## Positive: HLA-DQA1, CD79A, CD79B, HLA-DQB1, CD74
## Negative: IL7R, VIM, TMSB4X, S100A8, IL32
## PC_ 4
## Positive: TMSB10, MALAT1, LGALS2, S100A8, S100A9
## Negative: PF4, PPBP, SDPR, HIST1H2AC, SPARC
## PC_ 5
## Positive: GZMB, FGFBP2, NKG7, GNLY, CCL4
## Negative: LTB, VIM, IL7R, AQP3, KIAA0101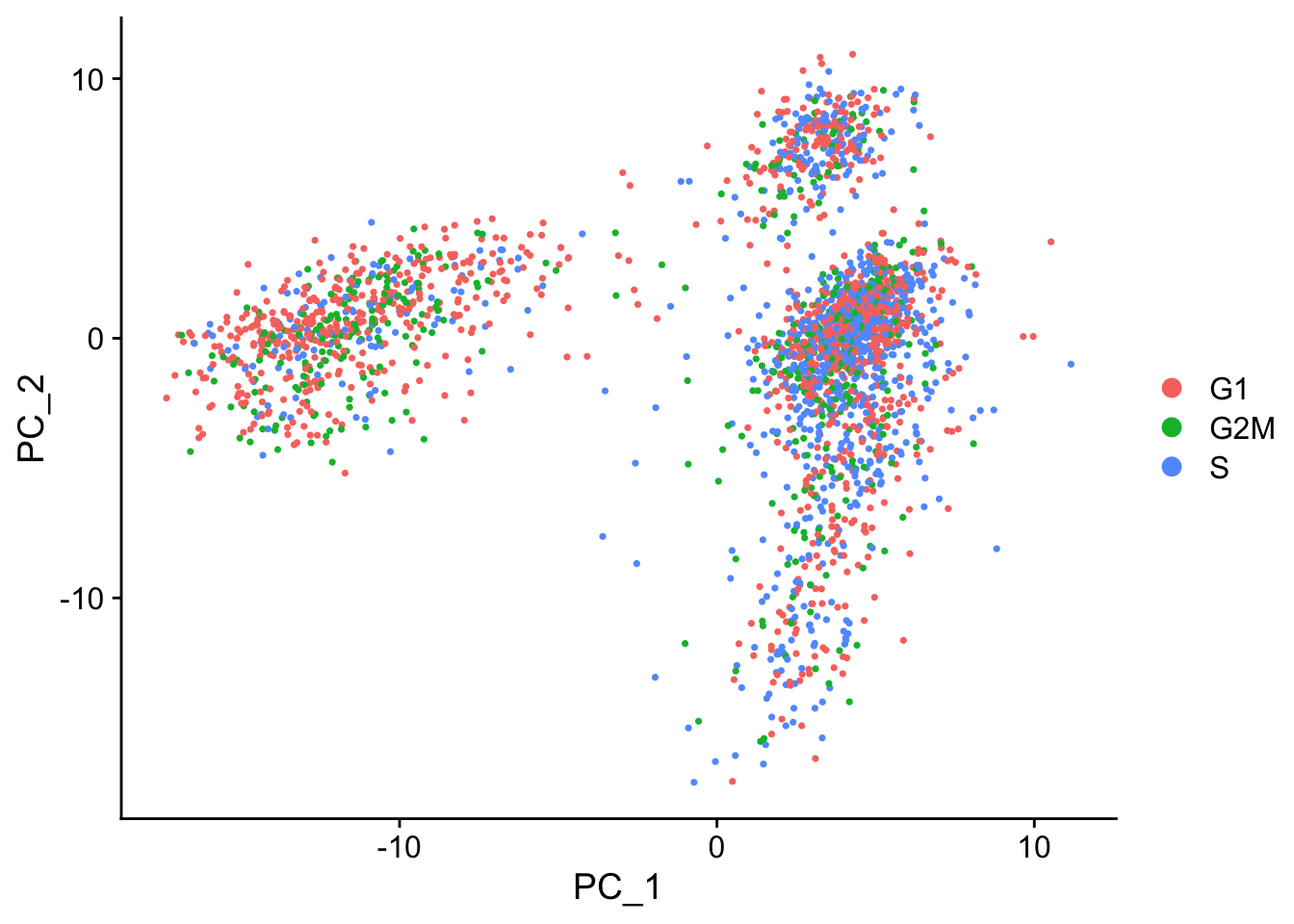
6.2.2.4 Perform linear dimensional reduction (ICA)
Task: Try running Independent Component Analysis. If you need help with the inputs try using the ?RunICA menu.
6.2.2.5 Visualizing ICA in Different Ways
# ProjectDim scores each gene in the dataset (including genes not included
# in the PCA) based on their correlation with the calculated components.
# Though we don't use this further here, it can be used to identify markers
# that are strongly correlated with cellular heterogeneity, but may not have
# passed through variable gene selection. The results of the projected PCA
# can be explored by setting use.full=T in the functions above
seurat <- ProjectDim(object = seurat, reduction = "pca")## PC_ 1
## Positive: MALAT1, LTB, IL32, IL7R, CD2, ACAP1, STK17A, CTSW, CD247, CCL5
## GIMAP5, AQP3, GZMA, CST7, TRAF3IP3, GZMK, MAL, HOPX, MYC, ETS1
## Negative: CST3, TYROBP, LST1, AIF1, FTL, FTH1, FCN1, LYZ, S100A9, TYMP
## FCER1G, CFD, LGALS1, LGALS2, S100A8, CTSS, SERPINA1, SPI1, IFITM3, PSAP
## PC_ 2
## Positive: CD79A, MS4A1, TCL1A, HLA-DQA1, HLA-DRA, HLA-DQB1, LINC00926, CD79B, HLA-DRB1, CD74
## HLA-DPB1, HLA-DMA, HLA-DQA2, HLA-DRB5, HLA-DPA1, HLA-DMB, HVCN1, FCRLA, LTB, BLNK
## Negative: NKG7, PRF1, GZMA, CST7, GZMB, FGFBP2, CTSW, GNLY, SPON2, GZMH
## CCL4, CCL5, FCGR3A, CD247, CLIC3, XCL2, AKR1C3, SRGN, HOPX, TTC38
## PC_ 3
## Positive: HLA-DQA1, CD79A, CD79B, HLA-DQB1, CD74, MS4A1, HLA-DPB1, HLA-DPA1, HLA-DRB1, HLA-DQA2
## HLA-DRA, HLA-DRB5, TCL1A, LINC00926, HLA-DMA, HLA-DMB, HVCN1, FCRLA, KIAA0125, IRF8
## Negative: IL7R, VIM, TMSB4X, S100A8, IL32, S100A6, S100A4, FYB, S100A9, MAL
## AQP3, RBP7, CD2, CD14, S100A10, LGALS2, S100A12, GIMAP4, NGFRAP1, ANXA1
## PC_ 4
## Positive: TMSB10, MALAT1, LGALS2, S100A8, S100A9, CD14, FCN1, LYZ, MS4A6A, S100A4
## CCL3, TYROBP, S100A6, ALDH2, GSTP1, FOLR3, RBP7, S100A10, S100A12, IFI6
## Negative: PF4, PPBP, SDPR, HIST1H2AC, SPARC, NRGN, GNG11, TSC22D1, RGS18, ACRBP
## TUBB1, MMD, ITGA2B, PTCRA, GP9, TMEM40, CMTM5, CA2, CLU, MAP3K7CL
## PC_ 5
## Positive: GZMB, FGFBP2, NKG7, GNLY, CCL4, PRF1, CST7, SPON2, GZMA, XCL2
## GZMH, CLIC3, CTSW, AKR1C3, TTC38, XCL1, CCL5, IGFBP7, S100A8, CCL3
## Negative: LTB, VIM, IL7R, AQP3, KIAA0101, PPA1, TYMS, LDHA, ZWINT, HN1
## MAL, ANXA5, CYTIP, CORO1B, IL32, CD2, TUBA1B, RRM2, PTGES3, TRADD6.2.2.6 Genes by PCs
Check other PCs to plot
Task: Check other PCs
seurat <- JackStraw(object = seurat, reduction = "pca")
seurat <- ScoreJackStraw(seurat, dims = 1:20)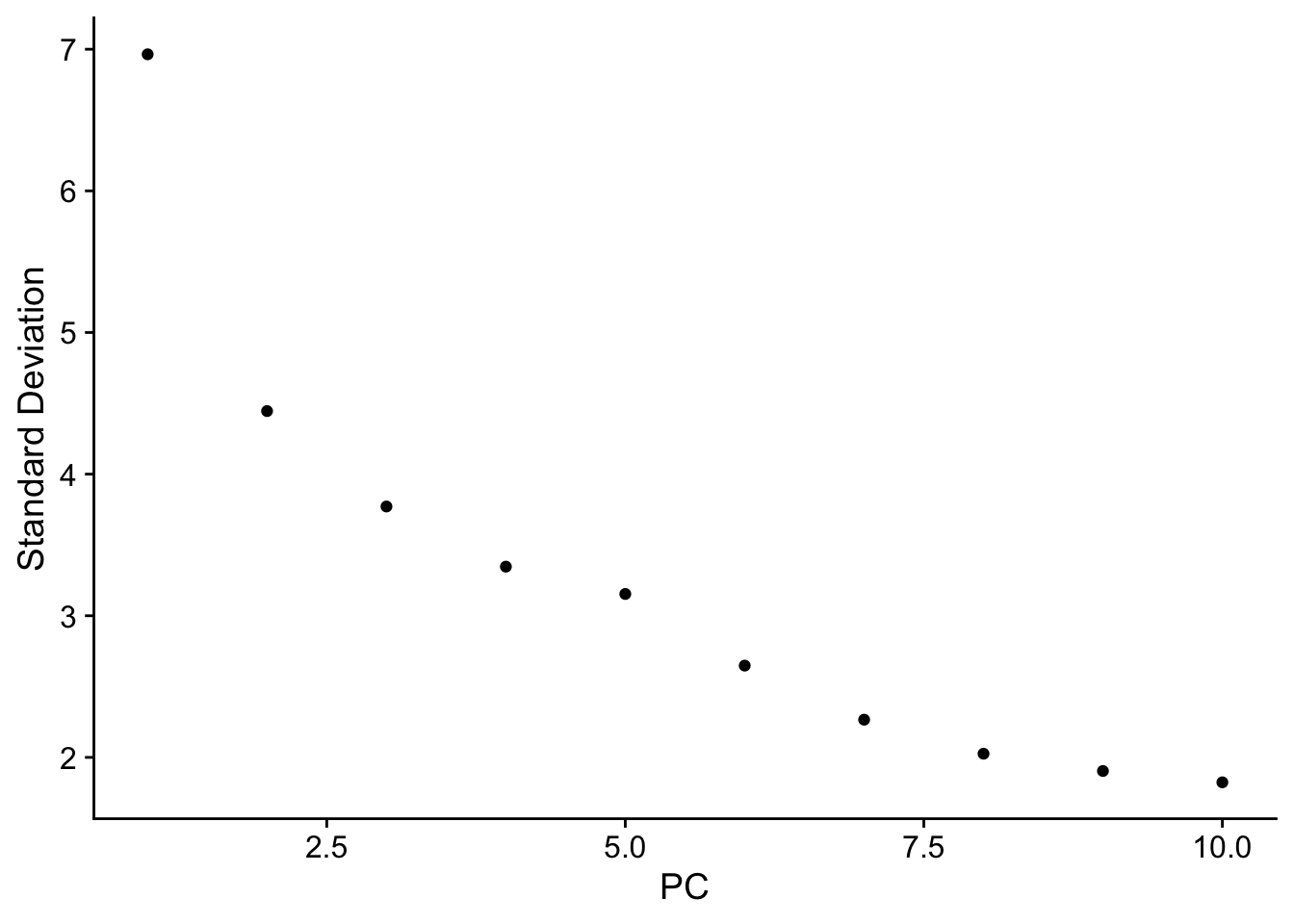
# save.SNN = T saves the SNN so that the clustering algorithm can be rerun
# using the same graph but with a different resolution value (see docs for
# full details)
set.seed(2020)
seurat <- FindNeighbors(object = seurat, dims = 1:10)## Computing nearest neighbor graph## Computing SNNseurat <- FindClusters(object = seurat,
reduction = "pca",
dims = 1:10,
resolution = 0.5,
random.seed = 2020)## Warning: The following arguments are not used: reduction, dims
## Warning: The following arguments are not used: reduction, dims## Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
##
## Number of nodes: 2655
## Number of edges: 97412
##
## Running Louvain algorithm...
## Maximum modularity in 10 random starts: 0.8712
## Number of communities: 8
## Elapsed time: 0 seconds6.2.3 Run non-linear dimensional reduction (UMAP/tSNE)
Seurat offers several non-linear dimensional reduction techniques, such as tSNE and UMAP, to visualize and explore these datasets. The goal of these algorithms is to learn the underlying manifold of the data in order to place similar cells together in low-dimensional space. Cells within the graph-based clusters determined above should co-localize on these dimension reduction plots. As input to the UMAP and tSNE, we suggest using the same PCs as input to the clustering analysis.
set.seed(2020)
seurat <- RunTSNE(seurat, reduction.use = "pca", dims.use = 1:10, perplexity=10)
# note that you can set do.label=T to help label individual clusters
DimPlot(object = seurat, reduction = "tsne")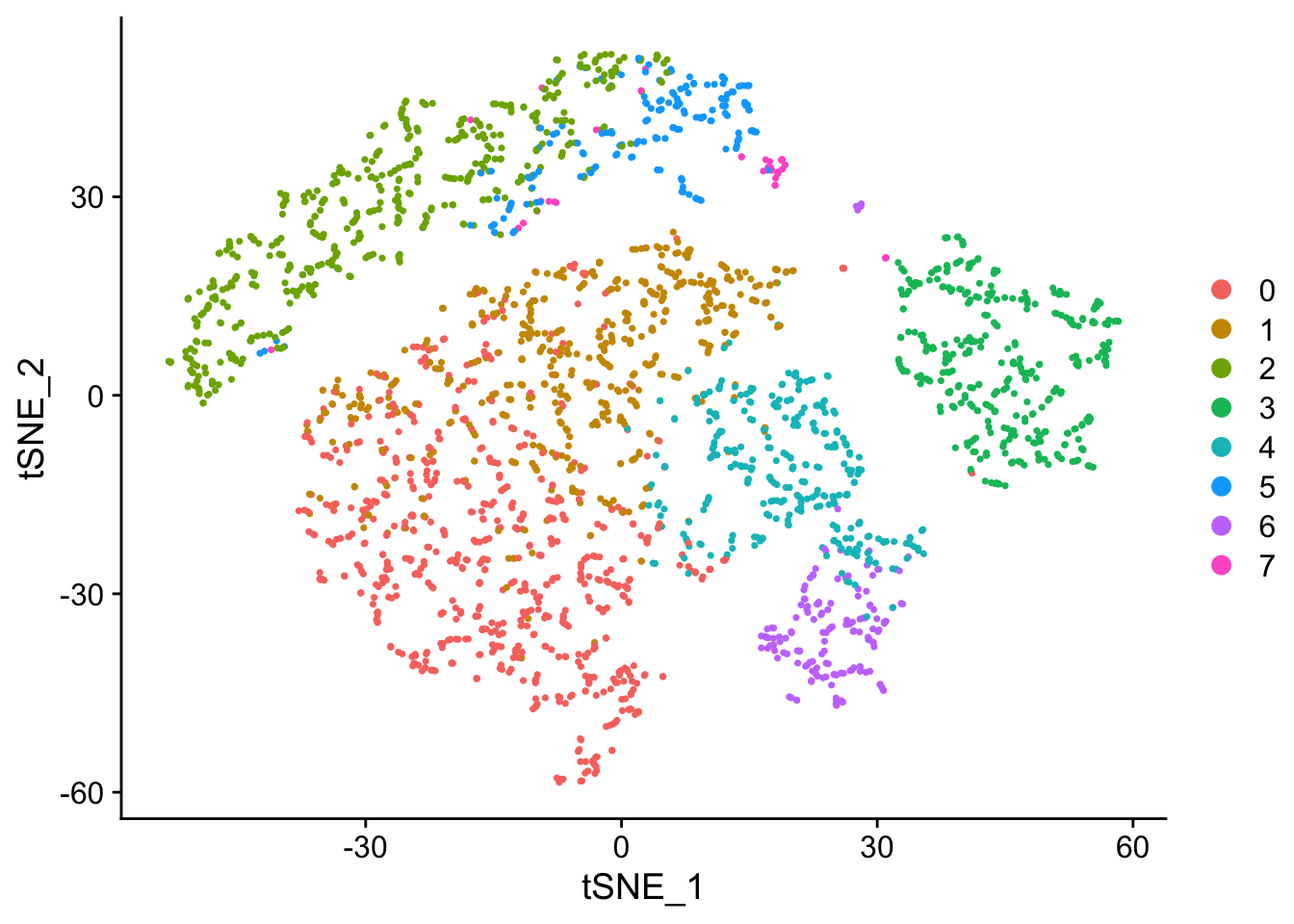
Task: Try using UMAP for the non-linear dimension reduction technique (hint: ?RunUMAP)
set.seed(2020)
seurat <- RunUMAP()
# note that you can set label=TRUE to help label individual clusters
DimPlot()6.2.3.1 Finding differentially expressed features (cluster biomarkers)
Seurat can help you find markers that define clusters via differential expression. By default, it identifes positive and negative markers of a single cluster (specified in ident.1), compared to all other cells. FindAllMarkers automates this process for all clusters, but you can also test groups of clusters vs. each other, or against all cells.
The min.pct argument requires a feature to be detected at a minimum percentage in either of the two groups of cells, and the thresh.test argument requires a feature to be differentially expressed (on average) by some amount between the two groups. You can set both of these to 0, but with a dramatic increase in time - since this will test a large number of features that are unlikely to be highly discriminatory. As another option to speed up these computations, max.cells.per.ident can be set. This will downsample each identity class to have no more cells than whatever this is set to. While there is generally going to be a loss in power, the speed increases can be significiant and the most highly differentially expressed features will likely still rise to the top.
# find all markers of cluster 1 using default parameters
cluster1.markers <- FindMarkers(object = seurat, ident.1 = 1, min.pct = 0.25)
head(cluster1.markers)## p_val avg_logFC pct.1 pct.2 p_val_adj
## LTB 2.398388e-95 0.8846283 0.982 0.643 3.285072e-91
## IL32 1.664226e-89 0.7966387 0.944 0.470 2.279490e-85
## LDHB 3.561648e-80 0.7142016 0.966 0.610 4.878389e-76
## IL7R 1.407429e-75 0.8335062 0.766 0.324 1.927756e-71
## CD3D 1.112564e-71 0.6199745 0.915 0.435 1.523880e-67
## AQP3 4.862610e-66 0.8776478 0.431 0.107 6.660317e-62Task: Try tuning different parameters. How does that affect results?
# find all markers distinguishing cluster 5 from clusters 0 and 1
cluster5.markers <- FindMarkers(object = seurat,
ident.1 = 5, ident.2 = c(0, 1),
min.pct = ??
test.use = ??,
only.pos = ??)
head(cluster5.markers)cluster3.markers <- FindMarkers(object = seurat,
ident.1 = 3,
thresh.use = 0.25,
test.use = "roc",
only.pos = TRUE)## Warning: The following arguments are not used: thresh.use## myAUC avg_diff power pct.1 pct.2
## CD74 0.984 2.029721 0.968 1.000 0.824
## CD79A 0.966 2.968324 0.932 0.938 0.043
## HLA-DRA 0.961 1.917675 0.922 1.000 0.492
## CD79B 0.949 2.394172 0.898 0.927 0.145
## HLA-DPB1 0.934 1.635536 0.868 0.988 0.447
## MS4A1 0.925 2.344449 0.850 0.865 0.053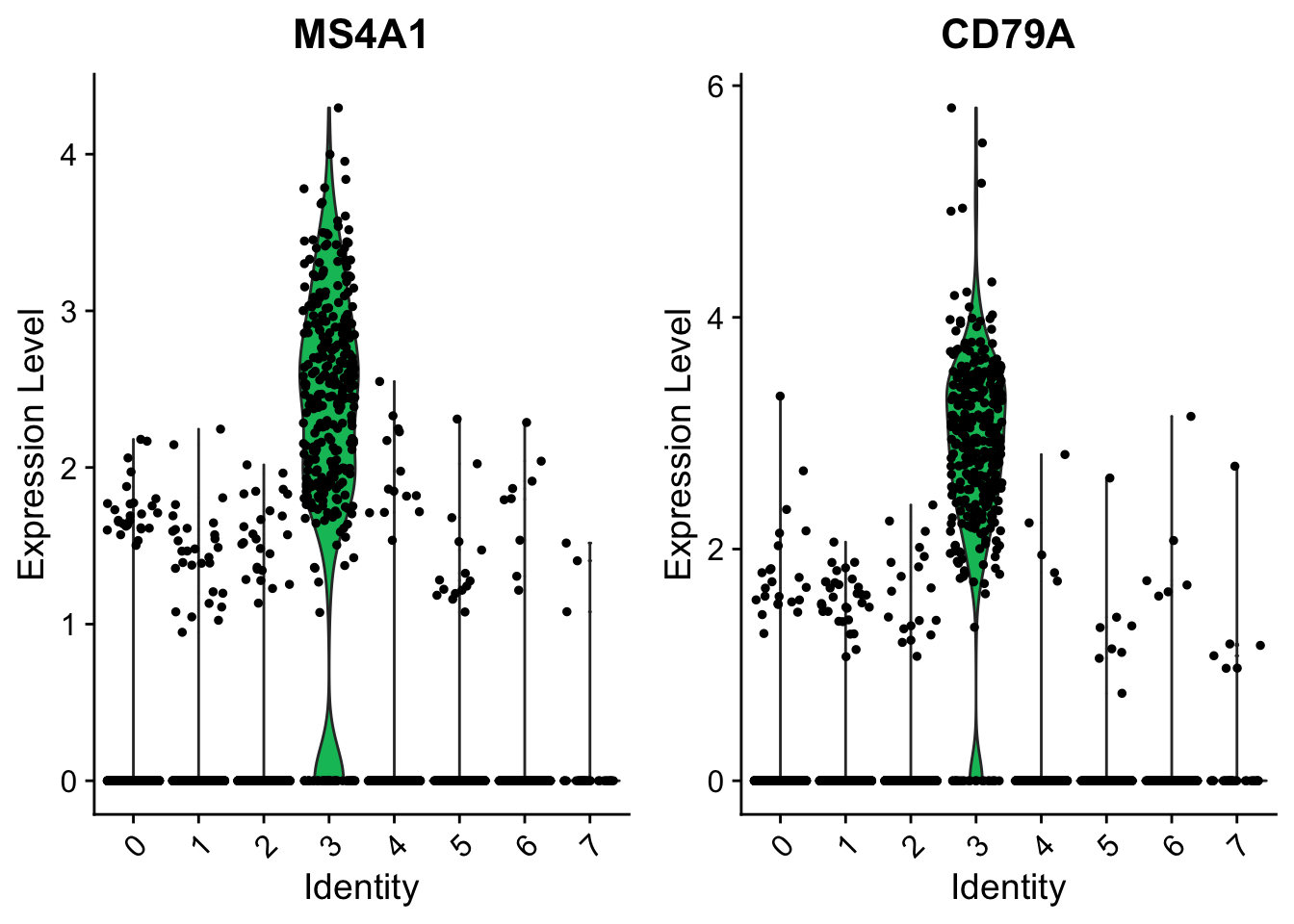
# you can plot raw UMI counts as well
VlnPlot(object = seurat,
features = c("NKG7", "PF4"),
log = TRUE)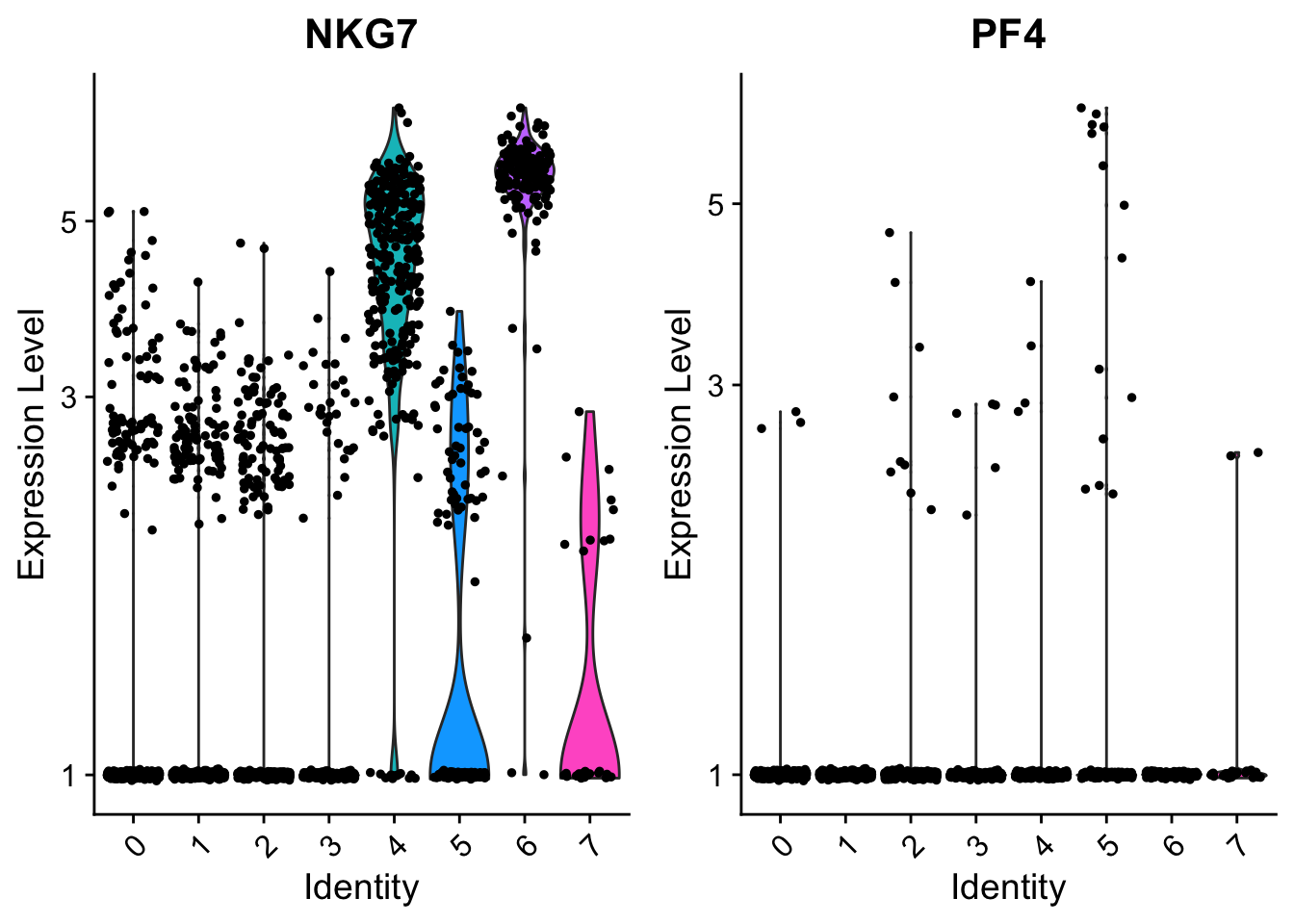
# find markers for every cluster compared to all remaining cells, report
# only the positive ones
pbmc.markers <- FindAllMarkers(object = seurat, only.pos = TRUE, min.pct = 0.25, thresh.use = 0.25)## Calculating cluster 0## Calculating cluster 1## Calculating cluster 2## Calculating cluster 3## Calculating cluster 4## Calculating cluster 5## Calculating cluster 6## Calculating cluster 7## # A tibble: 16 x 7
## # Groups: cluster [8]
## p_val avg_logFC pct.1 pct.2 p_val_adj cluster gene
## <dbl> <dbl> <dbl> <dbl> <dbl> <fct> <chr>
## 1 1.31e- 92 0.984 0.458 0.108 1.79e- 88 0 CCR7
## 2 1.08e- 49 0.747 0.345 0.108 1.48e- 45 0 PRKCQ-AS1
## 3 2.40e- 95 0.885 0.982 0.643 3.29e- 91 1 LTB
## 4 4.86e- 66 0.878 0.431 0.107 6.66e- 62 1 AQP3
## 5 0. 3.84 0.996 0.217 0. 2 S100A9
## 6 0. 3.77 0.971 0.123 0. 2 S100A8
## 7 0. 2.97 0.938 0.043 0. 3 CD79A
## 8 4.00e-276 2.50 0.63 0.022 5.48e-272 3 TCL1A
## 9 1.16e-196 2.12 0.964 0.237 1.59e-192 4 CCL5
## 10 2.16e-187 2.13 0.617 0.056 2.96e-183 4 GZMK
## 11 6.15e-171 2.26 0.929 0.137 8.43e-167 5 FCGR3A
## 12 4.31e-118 2.06 0.964 0.314 5.90e-114 5 LST1
## 13 6.72e-267 3.35 0.961 0.07 9.20e-263 6 GZMB
## 14 1.53e-175 3.42 0.935 0.135 2.10e-171 6 GNLY
## 15 9.11e-253 2.68 0.829 0.01 1.25e-248 7 FCER1A
## 16 6.56e- 23 1.96 1 0.51 8.98e- 19 7 HLA-DPB1FeaturePlot(object = seurat,
features = c("MS4A1", "GNLY", "CD3E", "CD14", "FCER1A", "FCGR3A", "LYZ", "PPBP", "CD8A"),
cols = c("grey", "blue"),
reduction = "tsne")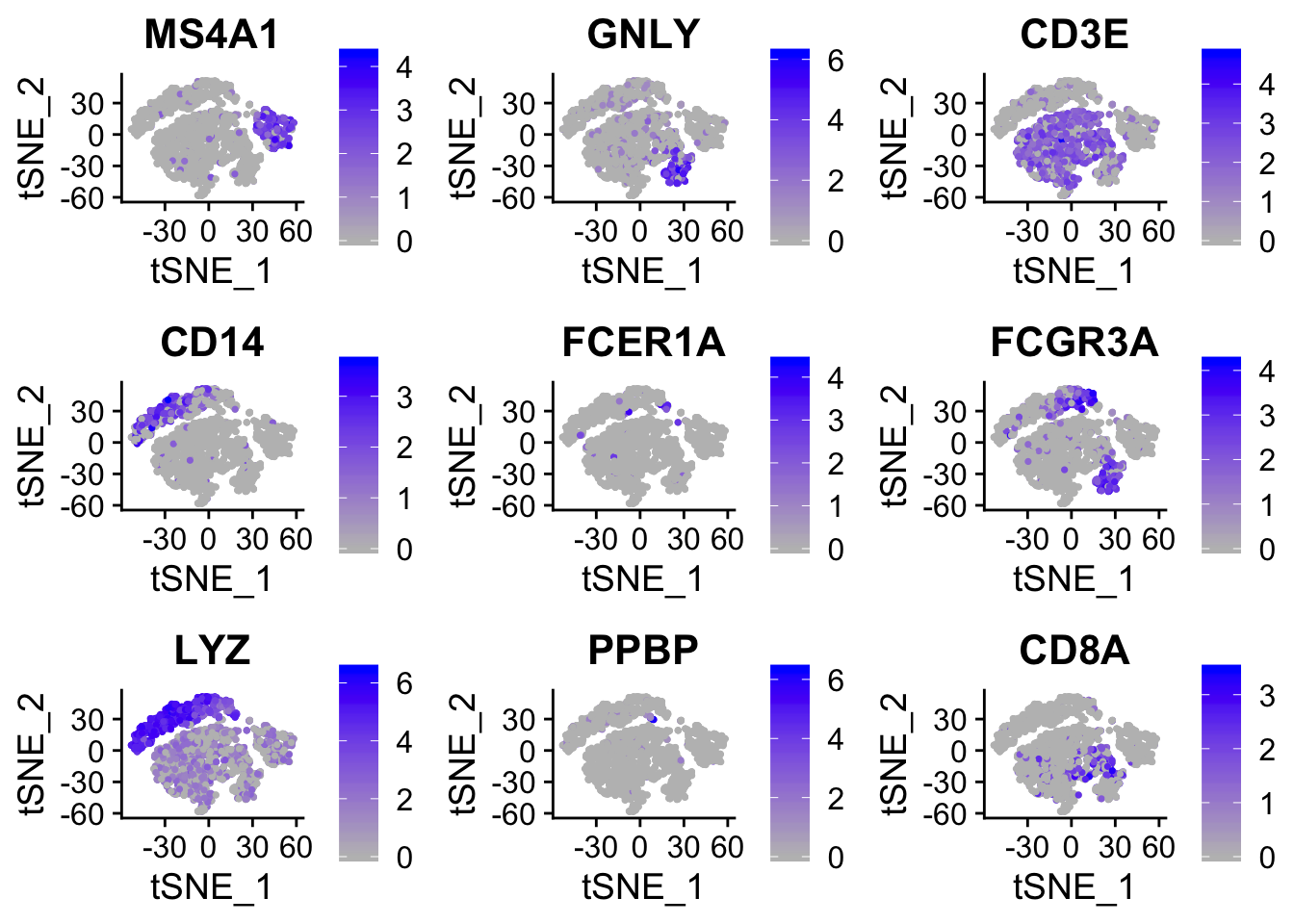
top10 <- pbmc.markers %>% group_by(cluster) %>% top_n(10, avg_logFC)
# setting slim.col.label to TRUE will print just the cluster IDS instead of
# every cell name
DoHeatmap(object = seurat, features = top10$gene, label = TRUE)## Warning in DoHeatmap(object = seurat, features = top10$gene,
## label = TRUE): The following features were omitted as they
## were not found in the scale.data slot for the RNA assay: RHOC,
## RP11-290F20.3, GZMM, CD8A, VPREB3, CD40LG, CD7, PIK3IP1, CD3E,
## NOSIP, LEF1, PRKCQ-AS1, CD3D, LDHB, CCR7, RPS3A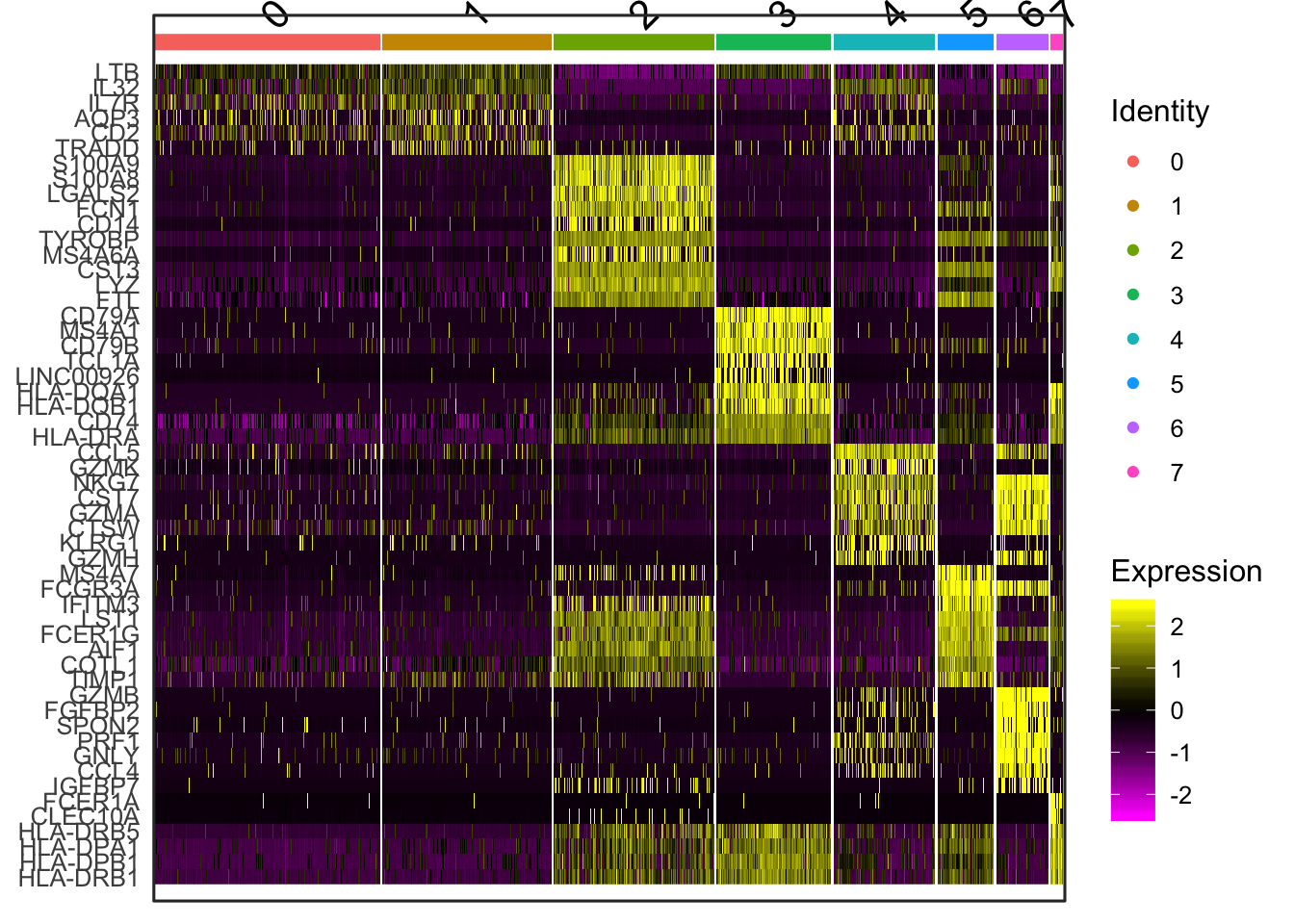
new.cluster.ids <- c("Memory CD4 T", "Naive CD4 T", "CD14+ Mono", "B", "CD8 T", "FCGR3A+ Mono", "NK", "DC", "Mk")
names(x = new.cluster.ids) <- levels(x = seurat)
seurat <- RenameIdents(object = seurat, new.cluster.ids)## Warning: Cannot find identity NA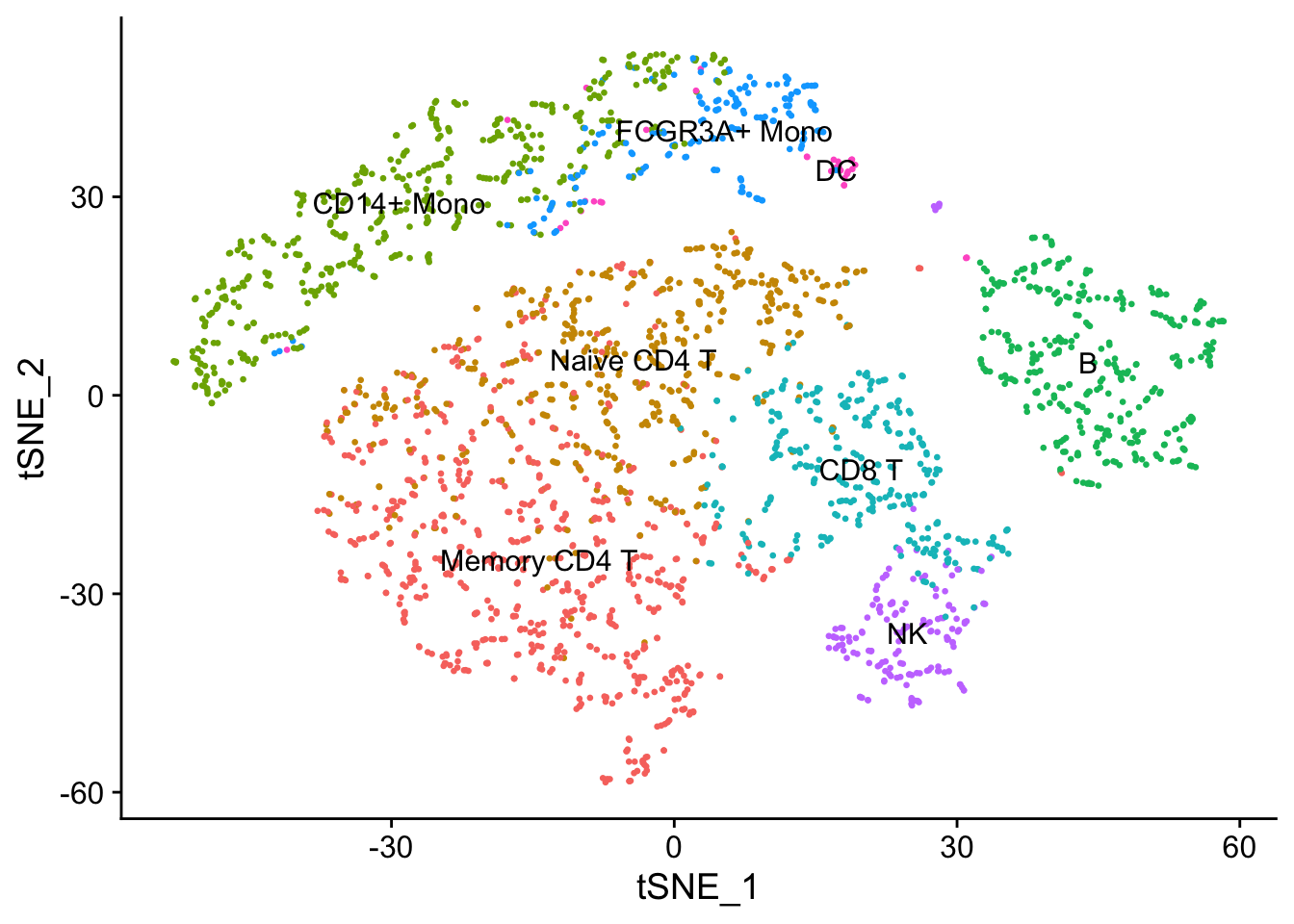
6.2.3.2 Further subdivisions within cell types
If you perturb some of our parameter choices above (for example, setting resolution=0.8 or changing the number of PCs), you might see the CD4 T cells subdivide into two groups. You can explore this subdivision to find markers separating the two T cell subsets. However, before reclustering (which will overwrite object@ident), we can stash our renamed identities to be easily recovered later.
# First lets stash our identities for later
seurat[["ClusterNames_0.6"]] <- Idents(object = seurat)
# Note that if you set save.snn=T above, you don't need to recalculate the
# SNN, and can simply put: pbmc <- FindClusters(pbmc,resolution = 0.8)
seurat <- FindClusters(object = seurat,
reduction = "pca",
dims = 1:10,
resolution = 0.8)## Warning: The following arguments are not used: reduction, dims
## Warning: The following arguments are not used: reduction, dims## Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
##
## Number of nodes: 2655
## Number of edges: 97412
##
## Running Louvain algorithm...
## Maximum modularity in 10 random starts: 0.8274
## Number of communities: 10
## Elapsed time: 0 secondsset.seed(2020)
## Warning in BuildSNN(object = object, genes.use = genes.use, reduction.type
## = reduction.type, : Build parameters exactly match those of already
## computed and stored SNN. To force recalculation, set force.recalc to TRUE.
# Demonstration of how to plot two tSNE plots side by side, and how to color
# points based on different criteria
plot1 <- DimPlot(object = seurat,
reduction= "tsne",
label = TRUE) + NoLegend()
plot2 <- DimPlot(object = seurat,
reduction = "tsne",
group.by = "ClusterNames_0.6",
label = TRUE) + NoLegend()
CombinePlots(list(plot1, plot2))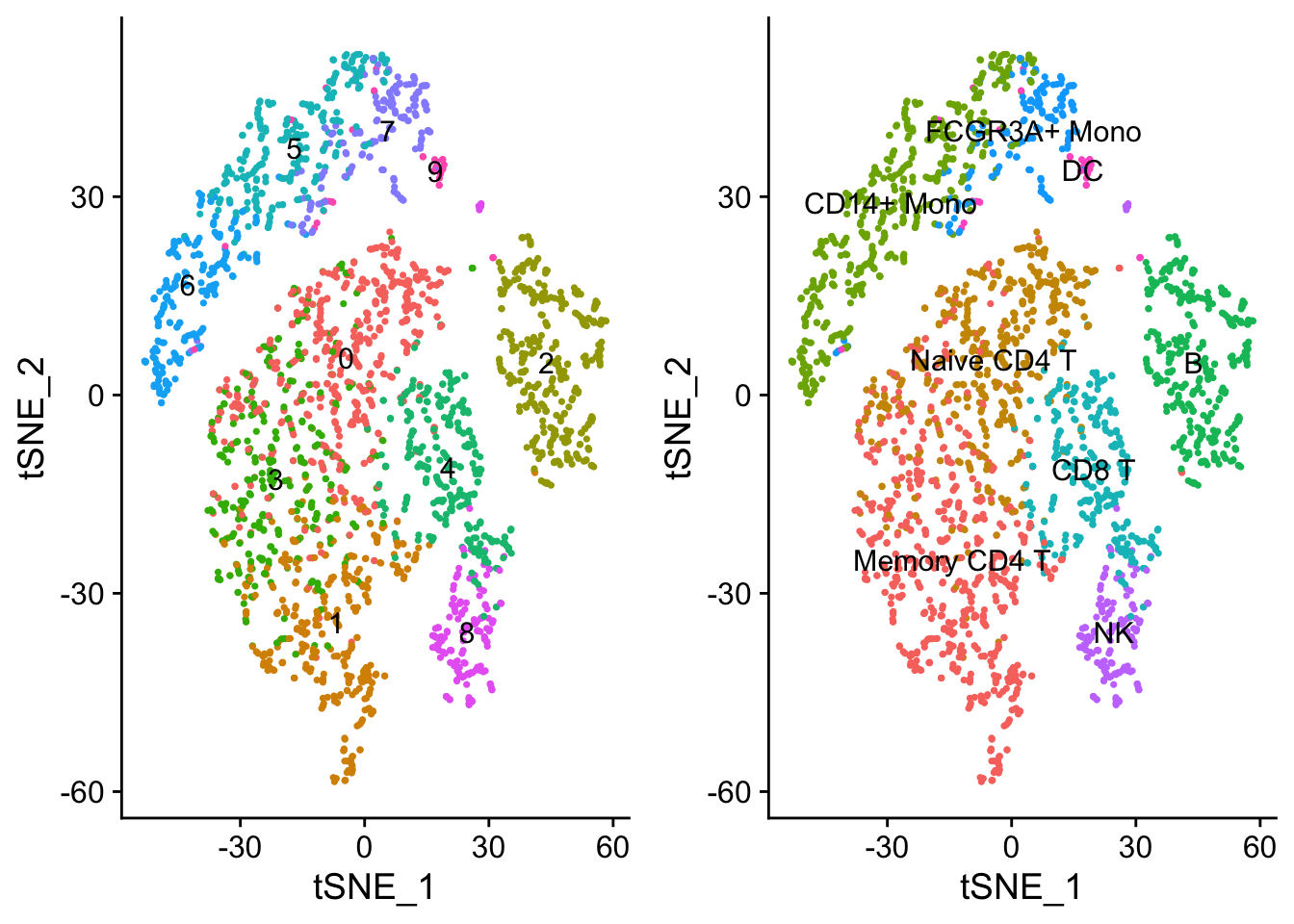
# Find discriminating markers
tcell.markers <- FindMarkers(object = seurat, ident.1 = 0, ident.2 = 1)
# Most of the markers tend to be expressed in C1 (i.e. S100A4). However, we
# can see that CCR7 is upregulated in C0, strongly indicating that we can
# differentiate memory from naive CD4 cells. cols demarcates the color
# palette from low to high expression
FeaturePlot(object = seurat, features = c("S100A4", "CCR7"), cols = c("green", "blue"))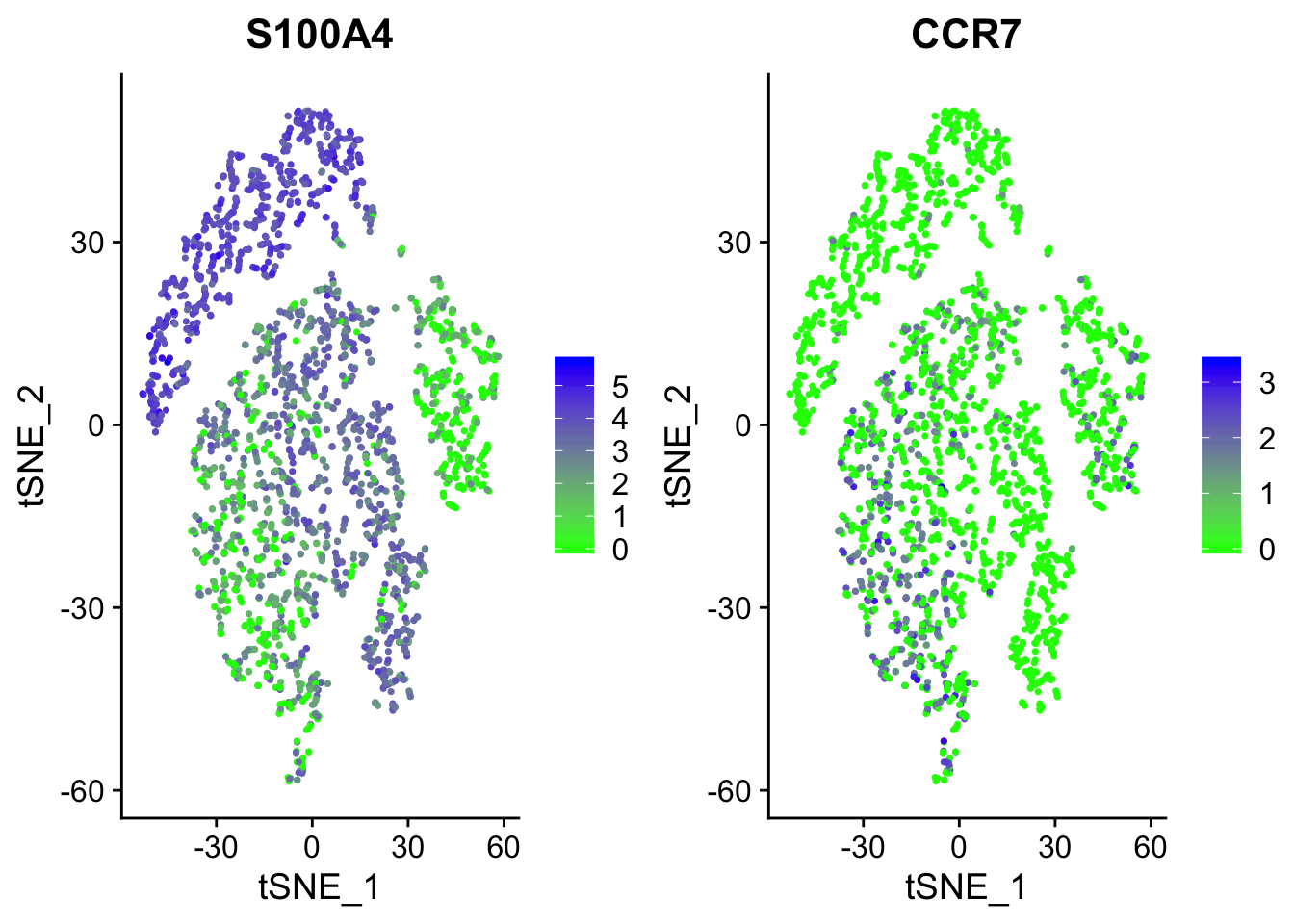
6.3 Feature Selection
6.3.1 Differential Expression Analysis
6.3.1.1 Differential Expression Tests
One of the most commonly performed tasks for RNA-seq data is differential gene expression (DE) analysis. Although well-established tools exist for such analysis in bulk RNA-seq data, methods for scRNA-seq data are just emerging. Given the special characteristics of scRNA-seq data, including generally low library sizes, high noise levels and a large fraction of so-called ‘dropout’ events, it is unclear whether DE methods that have been developed for bulk RNA-seq are suitable also for scRNA-seq. Check the help page out for the FindMarkers function by using ?FindMarkers
## Differential expression using t-test
FindMarkers(object = seurat, ident.1 = 0, ident.2 = 1, test.use = "t")Task: Try to use different test for diffential expression analysis (hint: ?FindMarkers)
6.3.2 Check Clusters
How do we test the cell types identified? How do we know how reliable they are?
Use Classifier to predict cell cluster. See how it predicts using hold out data. reference
# Assign the test object a three level attribute
groups <- sample(c("train", "test"), size = NROW(seurat@meta.data), replace = TRUE, prob = c(0.8, 0.2))
names(groups) <- colnames(seurat)
seurat <- AddMetaData(object = seurat, metadata = groups, col.name = "group")
# Find Anchors
seurat.list <- SplitObject(seurat, split.by = "group")
seurat.anchors <- FindIntegrationAnchors(object.list = seurat.list, dims = 1:30)## Computing 2000 integration features## Scaling features for provided objects## Finding all pairwise anchors## Running CCA## Merging objects## Finding neighborhoods## Finding anchors## Found 2597 anchors## Filtering anchors## Retained 1400 anchors## Extracting within-dataset neighbors## Merging dataset 1 into 2## Extracting anchors for merged samples## Finding integration vectors## Finding integration vector weights## Integrating data## Warning: Adding a command log without an assay associated with
## itseurat.query <- seurat.list[["train"]]
seurat.anchors <- FindTransferAnchors(reference = seurat.integrated,
query = seurat.query,
dims = 1:30)## Performing PCA on the provided reference using 2000 features as input.## Projecting PCA## Finding neighborhoods## Finding anchors## Found 6141 anchors## Filtering anchors## Retained 4729 anchors## Extracting within-dataset neighborspredictions <- TransferData(anchorset = seurat.anchors,
refdata = seurat.integrated$ClusterNames_0.6,
dims = 1:30)## Finding integration vectors## Finding integration vector weights## Predicting cell labelsseurat.query <- AddMetaData(seurat.query, metadata = predictions)
table(seurat.query@meta.data$ClusterNames_0.6, seurat.query@meta.data$predicted.id)##
## B CD14+ Mono CD8 T DC FCGR3A+ Mono
## Memory CD4 T 0 0 2 0 1
## Naive CD4 T 0 0 0 0 0
## CD14+ Mono 0 365 0 0 1
## B 268 0 0 0 0
## CD8 T 0 0 225 0 0
## FCGR3A+ Mono 0 8 0 0 130
## NK 1 0 7 0 0
## DC 0 1 0 28 0
##
## Memory CD4 T Naive CD4 T NK
## Memory CD4 T 542 11 0
## Naive CD4 T 53 334 0
## CD14+ Mono 0 0 0
## B 0 0 0
## CD8 T 12 7 0
## FCGR3A+ Mono 0 0 0
## NK 0 0 122
## DC 0 0 06.3.3 View Entire Object Structure
Notice all the slots and elements added to the object.
## Formal class 'Seurat' [package "Seurat"] with 12 slots
## ..@ assays :List of 1
## .. ..$ RNA:Formal class 'Assay' [package "Seurat"] with 8 slots
## .. .. .. ..@ counts :Formal class 'dgCMatrix' [package "Matrix"] with 6 slots
## .. .. .. .. .. ..@ i : int [1:2269052] 29 73 80 147 162 183 185 226 228 229 ...
## .. .. .. .. .. ..@ p : int [1:2656] 0 779 2131 3260 4220 4741 5522 6304 7094 7626 ...
## .. .. .. .. .. ..@ Dim : int [1:2] 13697 2655
## .. .. .. .. .. ..@ Dimnames:List of 2
## .. .. .. .. .. .. ..$ : chr [1:13697] "AL627309.1" "AP006222.2" "RP11-206L10.2" "RP11-206L10.9" ...
## .. .. .. .. .. .. ..$ : chr [1:2655] "AAACATACAACCAC" "AAACATTGAGCTAC" "AAACATTGATCAGC" "AAACCGTGCTTCCG" ...
## .. .. .. .. .. ..@ x : num [1:2269052] 1 1 2 1 1 1 1 41 1 1 ...
## .. .. .. .. .. ..@ factors : list()
## .. .. .. ..@ data :Formal class 'dgCMatrix' [package "Matrix"] with 6 slots
## .. .. .. .. .. ..@ i : int [1:2269052] 29 73 80 147 162 183 185 226 228 229 ...
## .. .. .. .. .. ..@ p : int [1:2656] 0 779 2131 3260 4220 4741 5522 6304 7094 7626 ...
## .. .. .. .. .. ..@ Dim : int [1:2] 13697 2655
## .. .. .. .. .. ..@ Dimnames:List of 2
## .. .. .. .. .. .. ..$ : chr [1:13697] "AL627309.1" "AP006222.2" "RP11-206L10.2" "RP11-206L10.9" ...
## .. .. .. .. .. .. ..$ : chr [1:2655] "AAACATACAACCAC" "AAACATTGAGCTAC" "AAACATTGATCAGC" "AAACCGTGCTTCCG" ...
## .. .. .. .. .. ..@ x : num [1:2269052] 1.64 1.64 2.23 1.64 1.64 ...
## .. .. .. .. .. ..@ factors : list()
## .. .. .. ..@ scale.data : num [1:2000, 1:2655] -0.8423 -0.2675 1.5408 -0.0487 -0.4588 ...
## .. .. .. .. ..- attr(*, "dimnames")=List of 2
## .. .. .. .. .. ..$ : chr [1:2000] "ISG15" "CPSF3L" "MRPL20" "ATAD3C" ...
## .. .. .. .. .. ..$ : chr [1:2655] "AAACATACAACCAC" "AAACATTGAGCTAC" "AAACATTGATCAGC" "AAACCGTGCTTCCG" ...
## .. .. .. ..@ key : chr "rna_"
## .. .. .. ..@ assay.orig : NULL
## .. .. .. ..@ var.features : chr [1:2000] "S100A9" "LYZ" "IGLL5" "GNLY" ...
## .. .. .. ..@ meta.features:'data.frame': 13697 obs. of 5 variables:
## .. .. .. .. ..$ vst.mean : num [1:13697] 0.00339 0.00113 0.00188 0.00113 0.00678 ...
## .. .. .. .. ..$ vst.variance : num [1:13697] 0.00338 0.00113 0.00188 0.00113 0.00674 ...
## .. .. .. .. ..$ vst.variance.expected : num [1:13697] 0.00364 0.00113 0.00196 0.00113 0.00748 ...
## .. .. .. .. ..$ vst.variance.standardized: num [1:13697] 0.928 0.999 0.961 0.999 0.901 ...
## .. .. .. .. ..$ vst.variable : logi [1:13697] FALSE FALSE FALSE FALSE FALSE FALSE ...
## .. .. .. ..@ misc : NULL
## ..@ meta.data :'data.frame': 2655 obs. of 13 variables:
## .. ..$ orig.ident : Factor w/ 1 level "10X_PBMC": 1 1 1 1 1 1 1 1 1 1 ...
## .. ..$ nCount_RNA : num [1:2655] 2419 4903 3147 2639 980 ...
## .. ..$ nFeature_RNA : int [1:2655] 779 1352 1129 960 521 781 782 790 532 550 ...
## .. ..$ percent.mt : num [1:2655] 3.02 3.79 0.89 1.74 1.22 ...
## .. ..$ S.Score : num [1:2655] 0.0825 -0.0276 -0.0124 0.0405 -0.0273 ...
## .. ..$ G2M.Score : num [1:2655] -0.0324 -0.0517 0.0833 0.0155 0.0334 ...
## .. ..$ Phase : Factor w/ 3 levels "G1","G2M","S": 3 1 2 3 2 1 1 2 1 3 ...
## .. ..$ old.ident : Factor w/ 1 level "10X_PBMC": 1 1 1 1 1 1 1 1 1 1 ...
## .. ..$ RNA_snn_res.0.5 : Factor w/ 8 levels "0","1","2","3",..: 2 4 2 6 7 2 5 5 1 6 ...
## .. ..$ seurat_clusters : Factor w/ 10 levels "0","1","2","3",..: 1 3 1 8 9 1 5 5 2 8 ...
## .. ..$ ClusterNames_0.6: Factor w/ 8 levels "Memory CD4 T",..: 2 4 2 6 7 2 5 5 1 6 ...
## .. ..$ RNA_snn_res.0.8 : Factor w/ 10 levels "0","1","2","3",..: 1 3 1 8 9 1 5 5 2 8 ...
## .. ..$ group : chr [1:2655] "test" "test" "train" "train" ...
## ..@ active.assay: chr "RNA"
## ..@ active.ident: Factor w/ 10 levels "0","1","2","3",..: 1 3 1 8 9 1 5 5 2 8 ...
## .. ..- attr(*, "names")= chr [1:2655] "AAACATACAACCAC" "AAACATTGAGCTAC" "AAACATTGATCAGC" "AAACCGTGCTTCCG" ...
## ..@ graphs :List of 2
## .. ..$ RNA_nn :Formal class 'Graph' [package "Seurat"] with 7 slots
## .. .. .. ..@ assay.used: chr "RNA"
## .. .. .. ..@ i : int [1:53100] 0 102 167 417 623 1207 1260 1835 2148 2155 ...
## .. .. .. ..@ p : int [1:2656] 0 12 32 51 75 86 90 126 153 164 ...
## .. .. .. ..@ Dim : int [1:2] 2655 2655
## .. .. .. ..@ Dimnames :List of 2
## .. .. .. .. ..$ : chr [1:2655] "AAACATACAACCAC" "AAACATTGAGCTAC" "AAACATTGATCAGC" "AAACCGTGCTTCCG" ...
## .. .. .. .. ..$ : chr [1:2655] "AAACATACAACCAC" "AAACATTGAGCTAC" "AAACATTGATCAGC" "AAACCGTGCTTCCG" ...
## .. .. .. ..@ x : num [1:53100] 1 1 1 1 1 1 1 1 1 1 ...
## .. .. .. ..@ factors : list()
## .. ..$ RNA_snn:Formal class 'Graph' [package "Seurat"] with 7 slots
## .. .. .. ..@ assay.used: chr "RNA"
## .. .. .. ..@ i : int [1:197479] 0 84 102 167 205 383 417 457 480 489 ...
## .. .. .. ..@ p : int [1:2656] 0 62 115 168 225 270 319 403 479 512 ...
## .. .. .. ..@ Dim : int [1:2] 2655 2655
## .. .. .. ..@ Dimnames :List of 2
## .. .. .. .. ..$ : chr [1:2655] "AAACATACAACCAC" "AAACATTGAGCTAC" "AAACATTGATCAGC" "AAACCGTGCTTCCG" ...
## .. .. .. .. ..$ : chr [1:2655] "AAACATACAACCAC" "AAACATTGAGCTAC" "AAACATTGATCAGC" "AAACCGTGCTTCCG" ...
## .. .. .. ..@ x : num [1:197479] 1 0.0811 0.1765 0.0811 0.1111 ...
## .. .. .. ..@ factors : list()
## ..@ neighbors : list()
## ..@ reductions :List of 2
## .. ..$ pca :Formal class 'DimReduc' [package "Seurat"] with 9 slots
## .. .. .. ..@ cell.embeddings : num [1:2655, 1:50] 5.28 1.22 1.89 -12.14 2.44 ...
## .. .. .. .. ..- attr(*, "dimnames")=List of 2
## .. .. .. .. .. ..$ : chr [1:2655] "AAACATACAACCAC" "AAACATTGAGCTAC" "AAACATTGATCAGC" "AAACCGTGCTTCCG" ...
## .. .. .. .. .. ..$ : chr [1:50] "PC_1" "PC_2" "PC_3" "PC_4" ...
## .. .. .. ..@ feature.loadings : num [1:2000, 1:50] -0.11749 -0.11826 0.00861 0.01508 -0.0136 ...
## .. .. .. .. ..- attr(*, "dimnames")=List of 2
## .. .. .. .. .. ..$ : chr [1:2000] "S100A9" "LYZ" "IGLL5" "GNLY" ...
## .. .. .. .. .. ..$ : chr [1:50] "PC_1" "PC_2" "PC_3" "PC_4" ...
## .. .. .. ..@ feature.loadings.projected: num [1:2000, 1:50] -7900 388 -1755 248 -1734 ...
## .. .. .. .. ..- attr(*, "dimnames")=List of 2
## .. .. .. .. .. ..$ : chr [1:2000] "ISG15" "CPSF3L" "MRPL20" "ATAD3C" ...
## .. .. .. .. .. ..$ : chr [1:50] "PC_1" "PC_2" "PC_3" "PC_4" ...
## .. .. .. ..@ assay.used : chr "RNA"
## .. .. .. ..@ global : logi FALSE
## .. .. .. ..@ stdev : num [1:50] 6.96 4.45 3.77 3.35 3.15 ...
## .. .. .. ..@ key : chr "PC_"
## .. .. .. ..@ jackstraw :Formal class 'JackStrawData' [package "Seurat"] with 4 slots
## .. .. .. .. .. ..@ empirical.p.values : num[0 , 0 ]
## .. .. .. .. .. ..@ fake.reduction.scores : num[0 , 0 ]
## .. .. .. .. .. ..@ empirical.p.values.full: num[0 , 0 ]
## .. .. .. .. .. ..@ overall.p.values : num[0 , 0 ]
## .. .. .. ..@ misc :List of 1
## .. .. .. .. ..$ total.variance: num 1721
## .. ..$ tsne:Formal class 'DimReduc' [package "Seurat"] with 9 slots
## .. .. .. ..@ cell.embeddings : num [1:2655, 1:2] 2.08 37.16 15.8 -10.98 22.77 ...
## .. .. .. .. ..- attr(*, "dimnames")=List of 2
## .. .. .. .. .. ..$ : chr [1:2655] "AAACATACAACCAC" "AAACATTGAGCTAC" "AAACATTGATCAGC" "AAACCGTGCTTCCG" ...
## .. .. .. .. .. ..$ : chr [1:2] "tSNE_1" "tSNE_2"
## .. .. .. ..@ feature.loadings : num[0 , 0 ]
## .. .. .. ..@ feature.loadings.projected: num[0 , 0 ]
## .. .. .. ..@ assay.used : chr "RNA"
## .. .. .. ..@ global : logi TRUE
## .. .. .. ..@ stdev : num(0)
## .. .. .. ..@ key : chr "tSNE_"
## .. .. .. ..@ jackstraw :Formal class 'JackStrawData' [package "Seurat"] with 4 slots
## .. .. .. .. .. ..@ empirical.p.values : num[0 , 0 ]
## .. .. .. .. .. ..@ fake.reduction.scores : num[0 , 0 ]
## .. .. .. .. .. ..@ empirical.p.values.full: num[0 , 0 ]
## .. .. .. .. .. ..@ overall.p.values : num[0 , 0 ]
## .. .. .. ..@ misc : list()
## ..@ project.name: chr "10X_PBMC"
## ..@ misc : list()
## ..@ version :Classes 'package_version', 'numeric_version' hidden list of 1
## .. ..$ : int [1:3] 3 1 2
## ..@ commands :List of 8
## .. ..$ NormalizeData.RNA :Formal class 'SeuratCommand' [package "Seurat"] with 5 slots
## .. .. .. ..@ name : chr "NormalizeData.RNA"
## .. .. .. ..@ time.stamp : POSIXct[1:1], format: ...
## .. .. .. ..@ assay.used : chr "RNA"
## .. .. .. ..@ call.string: chr [1:2] "NormalizeData(object = seurat, normalization.method = \"LogNormalize\", " " scale.factor = 10000)"
## .. .. .. ..@ params :List of 5
## .. .. .. .. ..$ assay : chr "RNA"
## .. .. .. .. ..$ normalization.method: chr "LogNormalize"
## .. .. .. .. ..$ scale.factor : num 10000
## .. .. .. .. ..$ margin : num 1
## .. .. .. .. ..$ verbose : logi TRUE
## .. ..$ FindVariableFeatures.RNA:Formal class 'SeuratCommand' [package "Seurat"] with 5 slots
## .. .. .. ..@ name : chr "FindVariableFeatures.RNA"
## .. .. .. ..@ time.stamp : POSIXct[1:1], format: ...
## .. .. .. ..@ assay.used : chr "RNA"
## .. .. .. ..@ call.string: chr [1:2] "FindVariableFeatures(object = seurat, mean.function = ExpMean, " " dispersion.function = LogVMR)"
## .. .. .. ..@ params :List of 12
## .. .. .. .. ..$ assay : chr "RNA"
## .. .. .. .. ..$ selection.method : chr "vst"
## .. .. .. .. ..$ loess.span : num 0.3
## .. .. .. .. ..$ clip.max : chr "auto"
## .. .. .. .. ..$ mean.function :function (x, ...)
## .. .. .. .. ..$ dispersion.function:function (x, ...)
## .. .. .. .. ..$ num.bin : num 20
## .. .. .. .. ..$ binning.method : chr "equal_width"
## .. .. .. .. ..$ nfeatures : num 2000
## .. .. .. .. ..$ mean.cutoff : num [1:2] 0.1 8
## .. .. .. .. ..$ dispersion.cutoff : num [1:2] 1 Inf
## .. .. .. .. ..$ verbose : logi TRUE
## .. ..$ ScaleData.RNA :Formal class 'SeuratCommand' [package "Seurat"] with 5 slots
## .. .. .. ..@ name : chr "ScaleData.RNA"
## .. .. .. ..@ time.stamp : POSIXct[1:1], format: ...
## .. .. .. ..@ assay.used : chr "RNA"
## .. .. .. ..@ call.string: chr [1:2] "ScaleData(object = seurat, vars.to.regress = c(\"batch\", " " \"percent.mt\"))"
## .. .. .. ..@ params :List of 11
## .. .. .. .. ..$ features : chr [1:2000] "S100A9" "LYZ" "IGLL5" "GNLY" ...
## .. .. .. .. ..$ assay : chr "RNA"
## .. .. .. .. ..$ vars.to.regress : chr [1:2] "batch" "percent.mt"
## .. .. .. .. ..$ model.use : chr "linear"
## .. .. .. .. ..$ use.umi : logi FALSE
## .. .. .. .. ..$ do.scale : logi TRUE
## .. .. .. .. ..$ do.center : logi TRUE
## .. .. .. .. ..$ scale.max : num 10
## .. .. .. .. ..$ block.size : num 1000
## .. .. .. .. ..$ min.cells.to.block: num 2655
## .. .. .. .. ..$ verbose : logi TRUE
## .. ..$ RunPCA.RNA :Formal class 'SeuratCommand' [package "Seurat"] with 5 slots
## .. .. .. ..@ name : chr "RunPCA.RNA"
## .. .. .. ..@ time.stamp : POSIXct[1:1], format: ...
## .. .. .. ..@ assay.used : chr "RNA"
## .. .. .. ..@ call.string: chr "RunPCA(object = seurat, ndims.print = 1:5, nfeatures.print = 5)"
## .. .. .. ..@ params :List of 10
## .. .. .. .. ..$ assay : chr "RNA"
## .. .. .. .. ..$ npcs : num 50
## .. .. .. .. ..$ rev.pca : logi FALSE
## .. .. .. .. ..$ weight.by.var : logi TRUE
## .. .. .. .. ..$ verbose : logi TRUE
## .. .. .. .. ..$ ndims.print : int [1:5] 1 2 3 4 5
## .. .. .. .. ..$ nfeatures.print: num 5
## .. .. .. .. ..$ reduction.name : chr "pca"
## .. .. .. .. ..$ reduction.key : chr "PC_"
## .. .. .. .. ..$ seed.use : num 42
## .. ..$ ProjectDim.RNA.pca :Formal class 'SeuratCommand' [package "Seurat"] with 5 slots
## .. .. .. ..@ name : chr "ProjectDim.RNA.pca"
## .. .. .. ..@ time.stamp : POSIXct[1:1], format: ...
## .. .. .. ..@ assay.used : chr "RNA"
## .. .. .. ..@ call.string: chr "ProjectDim(object = seurat, reduction = \"pca\")"
## .. .. .. ..@ params :List of 7
## .. .. .. .. ..$ reduction : chr "pca"
## .. .. .. .. ..$ assay : chr "RNA"
## .. .. .. .. ..$ dims.print : int [1:5] 1 2 3 4 5
## .. .. .. .. ..$ nfeatures.print: num 20
## .. .. .. .. ..$ overwrite : logi FALSE
## .. .. .. .. ..$ do.center : logi FALSE
## .. .. .. .. ..$ verbose : logi TRUE
## .. ..$ FindNeighbors.RNA.pca :Formal class 'SeuratCommand' [package "Seurat"] with 5 slots
## .. .. .. ..@ name : chr "FindNeighbors.RNA.pca"
## .. .. .. ..@ time.stamp : POSIXct[1:1], format: ...
## .. .. .. ..@ assay.used : chr "RNA"
## .. .. .. ..@ call.string: chr "FindNeighbors(object = seurat, dims = 1:10)"
## .. .. .. ..@ params :List of 13
## .. .. .. .. ..$ reduction : chr "pca"
## .. .. .. .. ..$ dims : int [1:10] 1 2 3 4 5 6 7 8 9 10
## .. .. .. .. ..$ assay : chr "RNA"
## .. .. .. .. ..$ k.param : num 20
## .. .. .. .. ..$ compute.SNN : logi TRUE
## .. .. .. .. ..$ prune.SNN : num 0.0667
## .. .. .. .. ..$ nn.method : chr "rann"
## .. .. .. .. ..$ annoy.metric: chr "euclidean"
## .. .. .. .. ..$ nn.eps : num 0
## .. .. .. .. ..$ verbose : logi TRUE
## .. .. .. .. ..$ force.recalc: logi FALSE
## .. .. .. .. ..$ do.plot : logi FALSE
## .. .. .. .. ..$ graph.name : chr [1:2] "RNA_nn" "RNA_snn"
## .. ..$ RunTSNE :Formal class 'SeuratCommand' [package "Seurat"] with 5 slots
## .. .. .. ..@ name : chr "RunTSNE"
## .. .. .. ..@ time.stamp : POSIXct[1:1], format: ...
## .. .. .. ..@ assay.used : chr "RNA"
## .. .. .. ..@ call.string: chr [1:2] "RunTSNE(seurat, reduction.use = \"pca\", dims.use = 1:10, " " perplexity = 10)"
## .. .. .. ..@ params :List of 9
## .. .. .. .. ..$ reduction : chr "pca"
## .. .. .. .. ..$ cells : chr [1:2655] "AAACATACAACCAC" "AAACATTGAGCTAC" "AAACATTGATCAGC" "AAACCGTGCTTCCG" ...
## .. .. .. .. ..$ dims : int [1:5] 1 2 3 4 5
## .. .. .. .. ..$ seed.use : num 1
## .. .. .. .. ..$ tsne.method : chr "Rtsne"
## .. .. .. .. ..$ add.iter : num 0
## .. .. .. .. ..$ dim.embed : num 2
## .. .. .. .. ..$ reduction.name: chr "tsne"
## .. .. .. .. ..$ reduction.key : chr "tSNE_"
## .. ..$ FindClusters :Formal class 'SeuratCommand' [package "Seurat"] with 5 slots
## .. .. .. ..@ name : chr "FindClusters"
## .. .. .. ..@ time.stamp : POSIXct[1:1], format: ...
## .. .. .. ..@ assay.used : chr "RNA"
## .. .. .. ..@ call.string: chr [1:2] "FindClusters(object = seurat, reduction = \"pca\", dims = 1:10, " " resolution = 0.8)"
## .. .. .. ..@ params :List of 10
## .. .. .. .. ..$ graph.name : chr "RNA_snn"
## .. .. .. .. ..$ modularity.fxn : num 1
## .. .. .. .. ..$ resolution : num 0.8
## .. .. .. .. ..$ method : chr "matrix"
## .. .. .. .. ..$ algorithm : num 1
## .. .. .. .. ..$ n.start : num 10
## .. .. .. .. ..$ n.iter : num 10
## .. .. .. .. ..$ random.seed : num 0
## .. .. .. .. ..$ group.singletons: logi TRUE
## .. .. .. .. ..$ verbose : logi TRUE
## ..@ tools : list()6.3.3.1 Probabilistic (LDA)
Another type of clustering we can do is a fuzzy or probablistic clustering. This is where cells are not assigned to specifically only one cluster. They get assigned a score for how much the cells belong to each of the clusters (sometimes called topics). This can be helpful for when your dataset continuous processes and/or cellular states as opposed to distinct cell types.
## [1] "clust_3" "clust_6"omega <- MouseDeng2014.FitGoM$clust_6$omega
annotation <- data.frame(
sample_id = paste0("X", c(1:NROW(omega))),
tissue_label = factor(rownames(omega),
levels = rev(c("zy", "early2cell", "mid2cell", "late2cell",
"4cell", "8cell", "16cell", "earlyblast", "midblast", "lateblast")))
)
rownames(omega) <- annotation$sample_id;
StructureGGplot(omega = omega,
annotation = annotation,
palette = RColorBrewer::brewer.pal(8, "Accent"),
yaxis_label = "Amplification batch",
order_sample = TRUE,
axis_tick = list(axis_ticks_length = .1,
axis_ticks_lwd_y = .1,
axis_ticks_lwd_x = .1,
axis_label_size = 7,
axis_label_face = "bold"))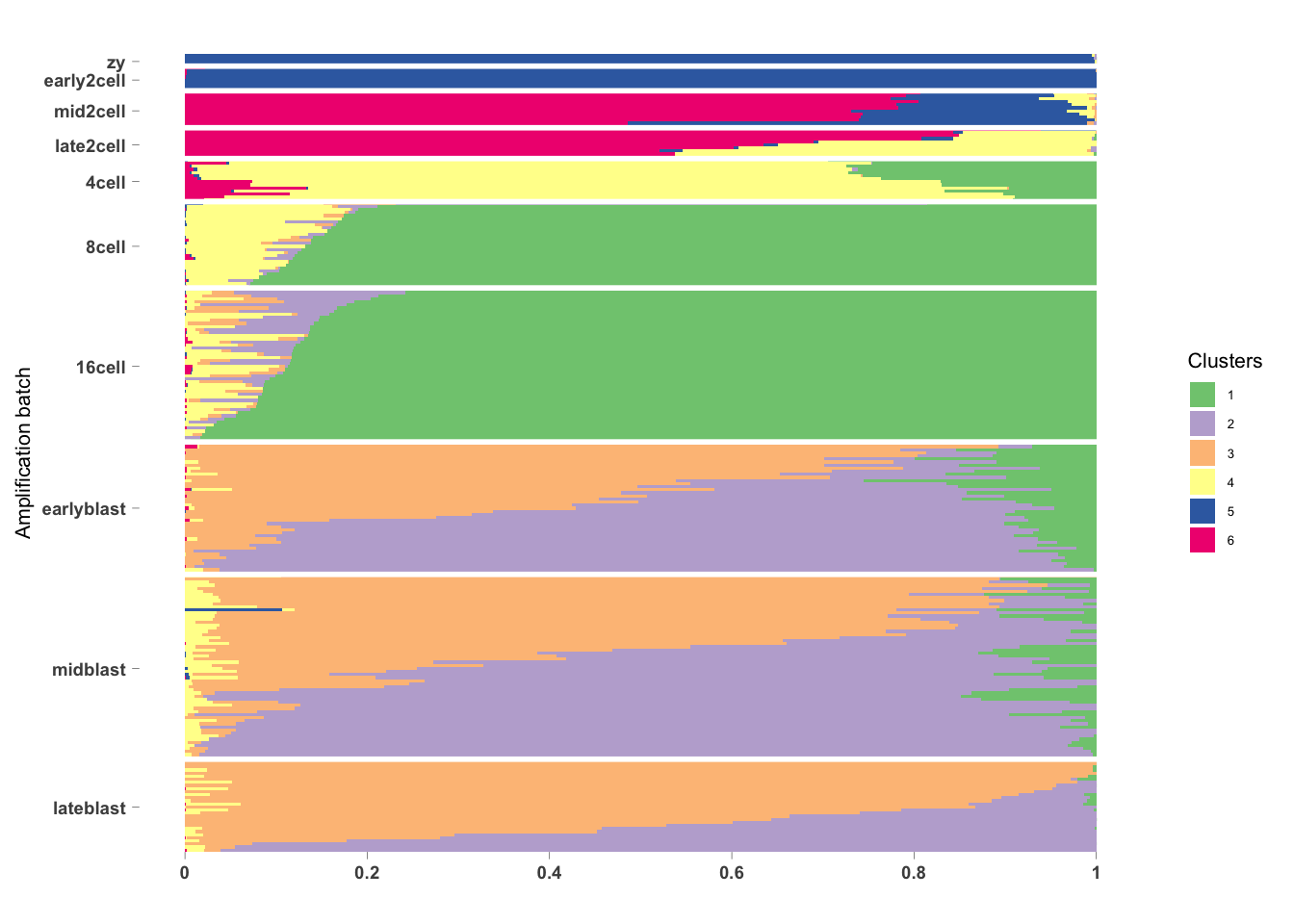
set.seed(2020)
## Preprocessing Steps
pbmc_small <- NormalizeData(object = pbmc_small, normalization.method = "LogNormalize", scale.factor = 10000)
pbmc_small <- RunPCA(object = pbmc_small)## Warning in irlba(A = t(x = object), nv = npcs, ...): You're
## computing too large a percentage of total singular values, use a
## standard svd instead.## Warning in irlba(A = t(x = object), nv = npcs, ...): did not
## converge--results might be invalid!; try increasing work or
## maxit## PC_ 1
## Positive: SDPR, PF4, PPBP, TUBB1, CA2, TREML1, MYL9, PGRMC1, RUFY1, PARVB
## VDAC3, IGLL5, AKR1C3, CD1C, RP11-290F20.3, GNLY, S100A8, S100A9, HLA-DQA1, HLA-DPB1
## Negative: HLA-DPB1, HLA-DQA1, S100A9, S100A8, GNLY, RP11-290F20.3, CD1C, AKR1C3, IGLL5, VDAC3
## PARVB, RUFY1, PGRMC1, MYL9, TREML1, CA2, TUBB1, PPBP, PF4, SDPR
## PC_ 2
## Positive: HLA-DPB1, HLA-DQA1, S100A8, S100A9, CD1C, RP11-290F20.3, PARVB, IGLL5, MYL9, SDPR
## PPBP, CA2, RUFY1, TREML1, PF4, TUBB1, PGRMC1, VDAC3, AKR1C3, GNLY
## Negative: GNLY, AKR1C3, VDAC3, PGRMC1, TUBB1, PF4, TREML1, RUFY1, CA2, PPBP
## SDPR, MYL9, IGLL5, PARVB, RP11-290F20.3, CD1C, S100A9, S100A8, HLA-DQA1, HLA-DPB1
## PC_ 3
## Positive: S100A9, S100A8, RP11-290F20.3, AKR1C3, PARVB, GNLY, PPBP, PGRMC1, MYL9, TUBB1
## CA2, TREML1, SDPR, VDAC3, PF4, RUFY1, HLA-DPB1, IGLL5, CD1C, HLA-DQA1
## Negative: HLA-DQA1, CD1C, IGLL5, HLA-DPB1, RUFY1, PF4, VDAC3, SDPR, TREML1, CA2
## TUBB1, MYL9, PGRMC1, PPBP, GNLY, PARVB, AKR1C3, RP11-290F20.3, S100A8, S100A9
## PC_ 4
## Positive: IGLL5, RP11-290F20.3, VDAC3, PPBP, TUBB1, TREML1, PF4, CA2, PARVB, MYL9
## SDPR, RUFY1, PGRMC1, S100A9, HLA-DQA1, HLA-DPB1, GNLY, S100A8, AKR1C3, CD1C
## Negative: CD1C, AKR1C3, S100A8, GNLY, HLA-DPB1, HLA-DQA1, S100A9, PGRMC1, RUFY1, SDPR
## MYL9, PARVB, CA2, PF4, TREML1, TUBB1, PPBP, VDAC3, RP11-290F20.3, IGLL5
## PC_ 5
## Positive: MYL9, PARVB, IGLL5, TREML1, AKR1C3, PGRMC1, HLA-DPB1, S100A9, TUBB1, PF4
## SDPR, GNLY, PPBP, S100A8, CA2, HLA-DQA1, CD1C, RUFY1, RP11-290F20.3, VDAC3
## Negative: VDAC3, RP11-290F20.3, RUFY1, CD1C, HLA-DQA1, CA2, S100A8, PPBP, GNLY, SDPR
## PF4, TUBB1, S100A9, HLA-DPB1, PGRMC1, AKR1C3, TREML1, IGLL5, PARVB, MYL9pbmc_small <- FindClusters(object = pbmc_small,
reduction = "pca",
dims.use = 1:10,
resolution = 1,
print.output = 0)## Warning: The following arguments are not used: reduction,
## dims.use, print.output## Suggested parameter: dims instead of dims.use; verbose instead of print.output## Warning: The following arguments are not used: reduction,
## dims.use, print.output## Suggested parameter: dims instead of dims.use; verbose instead of print.output## Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
##
## Number of nodes: 80
## Number of edges: 3124
##
## Running Louvain algorithm...
## Maximum modularity in 10 random starts: 0.1433
## Number of communities: 3
## Elapsed time: 0 seconds## Warning: Adding a command log without an assay associated with
## itpbmc_counts <- as.matrix(pbmc_small@assays$RNA@data)
pbmc_meta <- pbmc_small@meta.data
gene_names <- rownames(pbmc_counts)
pbmc_FitGoM <- FitGoM(t(pbmc_counts), K=4)## options not specified: switching to default BIC, other choice is BF for Bayes factor## Fitting a Grade of Membership model
## (Taddy M., AISTATS 2012, JMLR 22,
## http://proceedings.mlr.press/v22/taddy12/taddy12.pdf)##
## Estimating on a 80 document collection.
## Fit and Bayes Factor Estimation for K = 4
## log posterior increase: 1006, 69.7, 71, done.
## log BF( 4 ) = 5090.41omega <- data.frame(pbmc_FitGoM$fit$omega)
annotation <- data.frame(sample_id = rownames(omega),
tissue_label = paste0("cluster", pbmc_small@active.ident))
colnames(omega) <- paste0("topic", 1:4)
rownames(omega) <- annotation$sample_id;
StructureGGplot(omega = omega,
annotation = annotation,
palette = RColorBrewer::brewer.pal(4, "Dark2"),
yaxis_label = "Cells",
order_sample = TRUE,
axis_tick = list(axis_ticks_length = .1,
axis_ticks_lwd_y = .1,
axis_ticks_lwd_x = .1,
axis_label_size = 7,
axis_label_face = "bold"))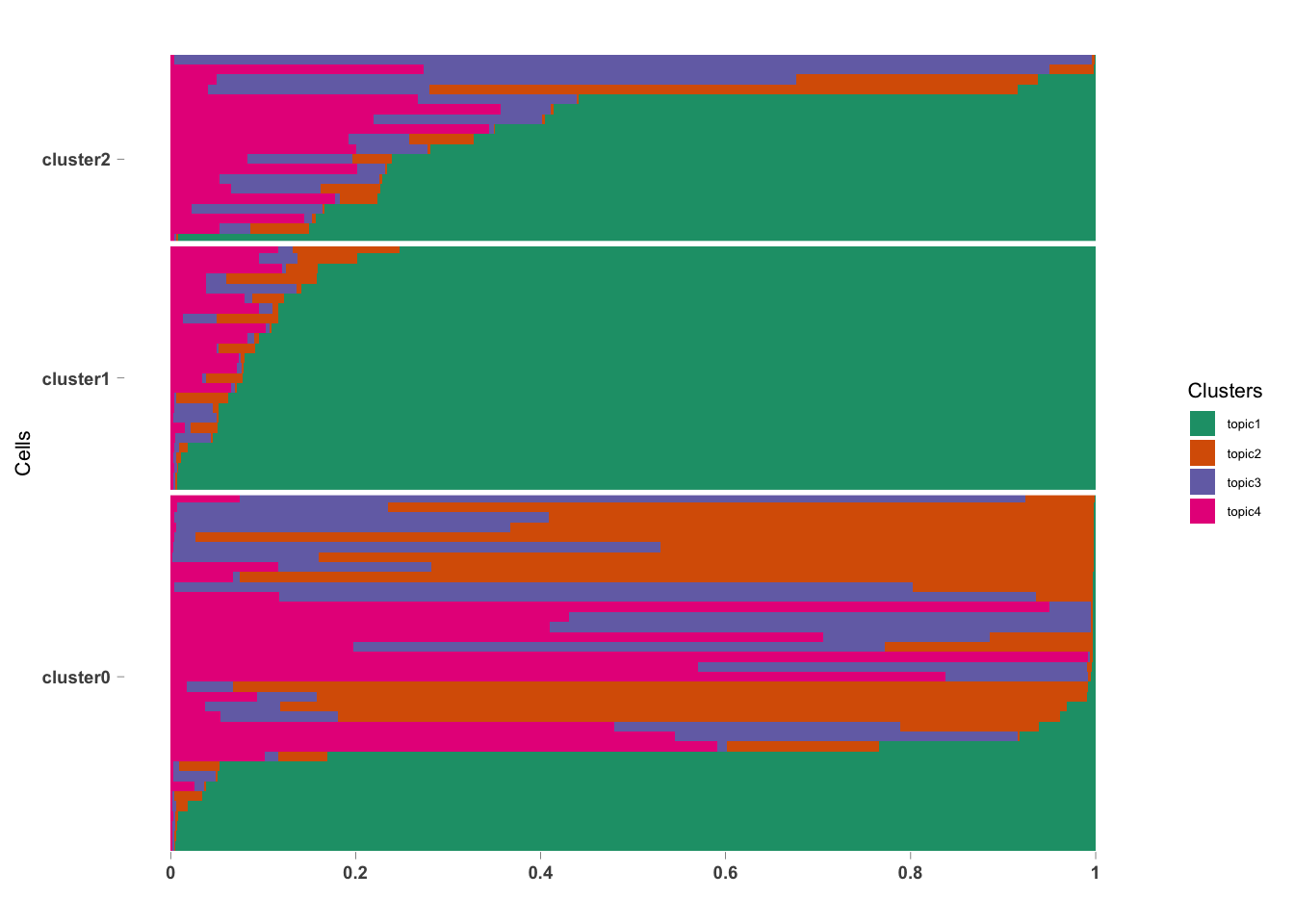
# ## Add Topic Scores to Meta Data Part of the Seurat Object
pbmc_small <- AddMetaData(pbmc_small, omega)pbmc_small@meta.data %>%
group_by(RNA_snn_res.1) %>%
summarise(topic1 = mean(topic1),
topic2 = mean(topic2),
topic3 = mean(topic3),
topic4 = mean(topic4))## # A tibble: 3 x 5
## RNA_snn_res.1 topic1 topic2 topic3 topic4
## <fct> <dbl> <dbl> <dbl> <dbl>
## 1 0 0.281 0.290 0.221 0.207
## 2 1 0.913 0.0253 0.0170 0.0450
## 3 2 0.595 0.0663 0.194 0.145## ggplot object, you can add layers
p1 <- DimPlot(pbmc_small, reduction = "tsne") + labs(title = "Resolution 1") ## return ggplot object
p1
p2 <- FeaturePlot(object = pbmc_small,
features = c("topic1", "topic2", "topic3", "topic4"),
cols = c("grey", "blue"),
reduction = "tsne") ## return ggplot object
p2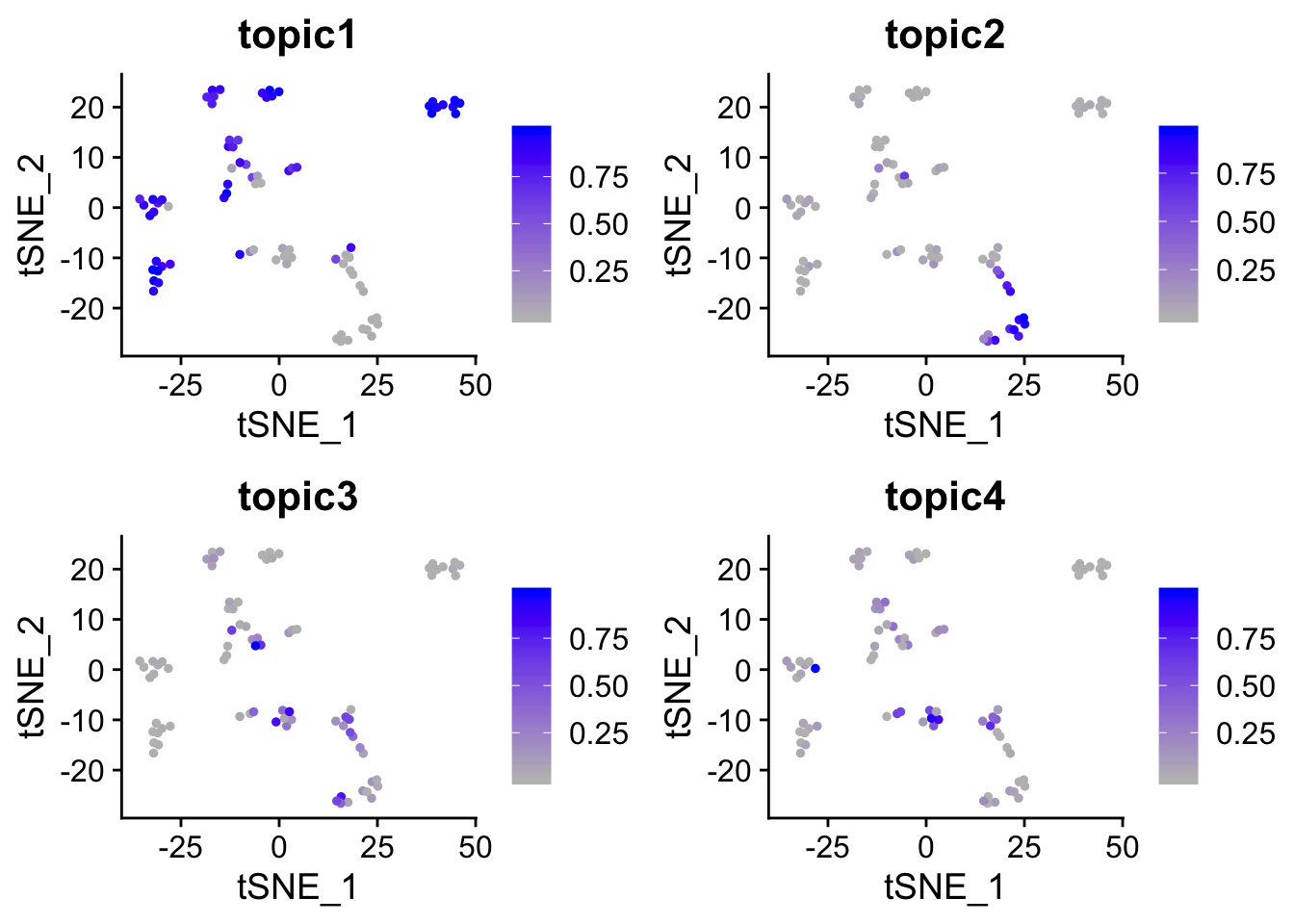
## Warning: Graphs cannot be vertically aligned unless the axis
## parameter is set. Placing graphs unaligned.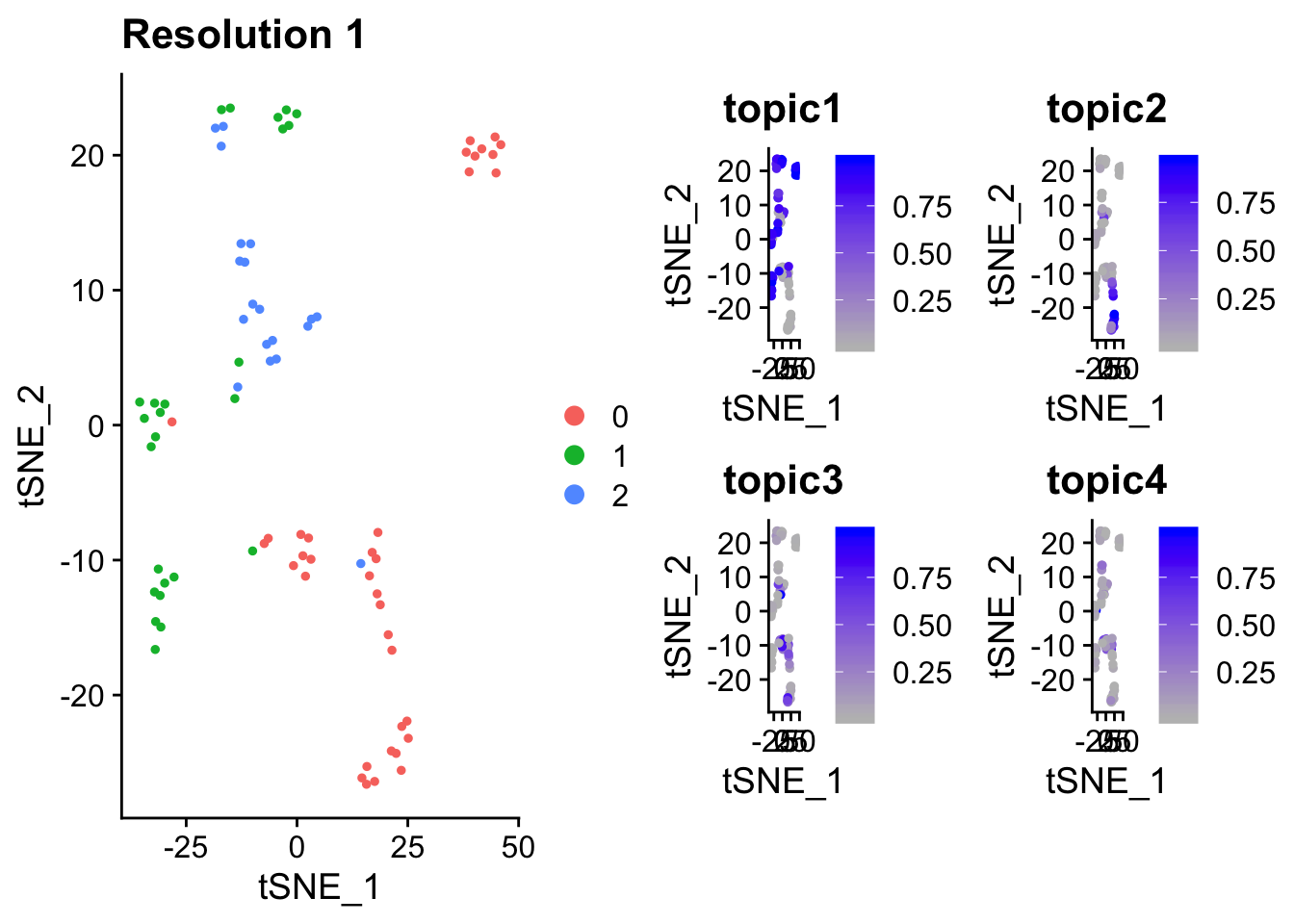
6.3.3.2 Extract Top Feature
theta_mat <- pbmc_FitGoM$fit$theta
top_features <- ExtractTopFeatures(theta_mat,
top_features=100,
method="poisson",
options="min")
gene_list <- do.call(rbind,
lapply(1:dim(top_features$indices)[1],
function(x) gene_names[top_features$indices[x,]]))We tabulate the top 5 genes for these 4 topics
out_table <- do.call(rbind, lapply(1:4, function(i) toString(gene_list[i,1:5])))
rownames(out_table) <- paste("Topic", c(1:4))
out_table## [,1]
## Topic 1 "GRN, HLA-DMB, IFI30, LY86, PF4"
## Topic 2 "GNLY, GZMB, PRF1, GZMH, CCL4"
## Topic 3 "GZMK, HNRNPH1, SATB1, SIT1, CRBN"
## Topic 4 "PIK3IP1, TNFAIP8, THYN1, SP100, CCR7"