4 Data Wrangling scRNAseq
4.1 Goal
- To give you experience with the analysis of single cell RNA sequencing (scRNA-seq) including performing quality control and identifying cell type subsets.
- To introduce you to scRNA-seq analysis using the Seurat package.
4.2 Introduction
Data produced in a single cell RNA-seq experiment has several interesting characteristics that make it distinct from data produced in a bulk population RNA-seq experiment. Two characteristics that are important to keep in mind when working with scRNA-Seq are drop-out (the excessive amount of zeros due to limiting mRNA) and the potential for quality control (QC) metrics to be confounded with biology. This combined with the ability to measure heterogeniety from cells in samples has shifted the field away from the typical analysis in population-based RNA-Seq. Here we demonstrate some approaches to quality control, followed by identifying and analyzing cell subsets.
For this tutorial, we will be analyzing the a dataset of Non-Small Cell Lung Cancer Cells (NSCLC) freely available from 10X Genomics (https://support.10xgenomics.com/single-cell-vdj/datasets/2.2.0/vdj_v1_hs_nsclc_5gex), using the Seurat R package (http://satijalab.org/seurat/), a popular and powerful set of tools to conduct scRNA-seq analysis in R. In this dataset, there are 7802 single cells that were sequenced on the Illumina NovaSeq 6000. Please note this tutorial borrows heavily from Seurat’s tutorials, so feel free to go through them in more detail.
4.2.1 Load necessary packages
When loading libraries, we are asking R to load code for us written by someone else. It is a convenient way to leverage and reproduce methodology developed by others.
4.2.2 Read in NSCLC counts matrix.
The data for Non-Small Cell Lung Cancer Cells (NSCLC) is freely available from 10X Genomics (https://support.10xgenomics.com/single-cell-vdj/datasets/2.2.0/vdj_v1_hs_nsclc_5gex). We start by reading in the counts matrix generated by the Cell Ranger count program.
Task: Change the directory name to mydir/ where you saved your data
Task: Check the dirname to dir where you saved your data
4.2.3 Let’s examine the sparse counts matrix
## 10 x 3 sparse Matrix of class "dgCMatrix"
## AAACCTGAGCTAGTCT AAACCTGAGGGCACTA
## RP11-34P13.3 . .
## FAM138A . .
## OR4F5 . .
## RP11-34P13.7 . .
## RP11-34P13.8 . .
## RP11-34P13.14 . .
## RP11-34P13.9 . .
## FO538757.3 . .
## FO538757.2 . .
## AP006222.2 . .
## AAACCTGAGTACGTTC
## RP11-34P13.3 .
## FAM138A .
## OR4F5 .
## RP11-34P13.7 .
## RP11-34P13.8 .
## RP11-34P13.14 .
## RP11-34P13.9 .
## FO538757.3 .
## FO538757.2 .
## AP006222.2 .Here we see the upper left corner of the sparse matrix. The columns are indexed by 10x cell barcodes (each 16 nt long), and the rows are the gene names. We mentioned these matrices are sparse, here we see only zeroes (indicated by the “.” symbol); this is the most common value in these sparse matrices. Next, let us look at the dimensions of this matrix.
4.2.4 How big is the matrix?
## [1] 33694 7802Here we see the counts matrix has 33694 genes and 7802 cells.
4.2.5 How much memory does a sparse matrix take up relative to a dense matrix?
## 169457000 bytes## 2106010424 bytesWe see here that the sparse matrix takes 225 Mb in memory while storing the matrix in a dense format (where all count values including zeros are stored) takes almost 10 times as much memory! This memory saving is very important, especially as data sets are now being created that are beyond a million cells. These matrices can become unmanageable without special computing resources.
In the sparse representation, we assume that the majority of count values in a matrix are zero. We only store the non-zero values. This is implemented in the Matrix package using a dgTMatrix object.
4.3 Filtering low-quality cells
You can learn a lot about your scRNA-seq data’s quality with simple plotting. Let’s do some plotting to look at the number of reads per cell, reads per genes, expressed genes per cell (often called complexity), and rarity of genes (cells expressing genes).
4.3.1 Look at the summary counts for genes and cells
counts_per_cell <- Matrix::colSums(counts)
cat("counts per cell: ", counts_per_cell[1:5], "\n") ## counts for first 5 cells## counts per cell: 3605 3828 6457 3075 9400counts_per_gene <- Matrix::rowSums(counts)
cat("counts per gene: ", counts_per_gene[1:5], "\n") ## counts for first 5 genes## counts per gene: 2 0 0 2 0genes_per_cell <- Matrix::colSums(counts > 0) # count gene only if it has non-zero reads mapped.
cat("counts for non-zero genes: ", genes_per_cell[1:5]) ## counts for first 5 genes## counts for non-zero genes: 1184 1387 1784 1092 2626Task: In a similar way, can you calculate cells per genes? replace the ‘?’ in the command below
#### cells_per_gene <- Matrix::?(counts>?) # only count cells where the gene is expressed
cells_per_gene <- # only count cells where the gene is expressed
cat("count of cells with expressed genes: ", cells_per_gene)colSums and rowSums are functions that work on each row or column in a matrix and return the column sums or row sums as a vector. If this is true counts_per_cell should have 1 entry per cell. Let’s make sure the length of the returned vector matches the matrix dimension for column. How would you do that? ( Hint:length() ).
Notes: 1. Matrix::colSums is a way to force functions from the Matrix library to be used. There are many libraries that implement colSums, we are forcing the one from the Matrix library to be used here to make sure it handles the dgTmatrix (sparse matrix) correctly. This is good practice.
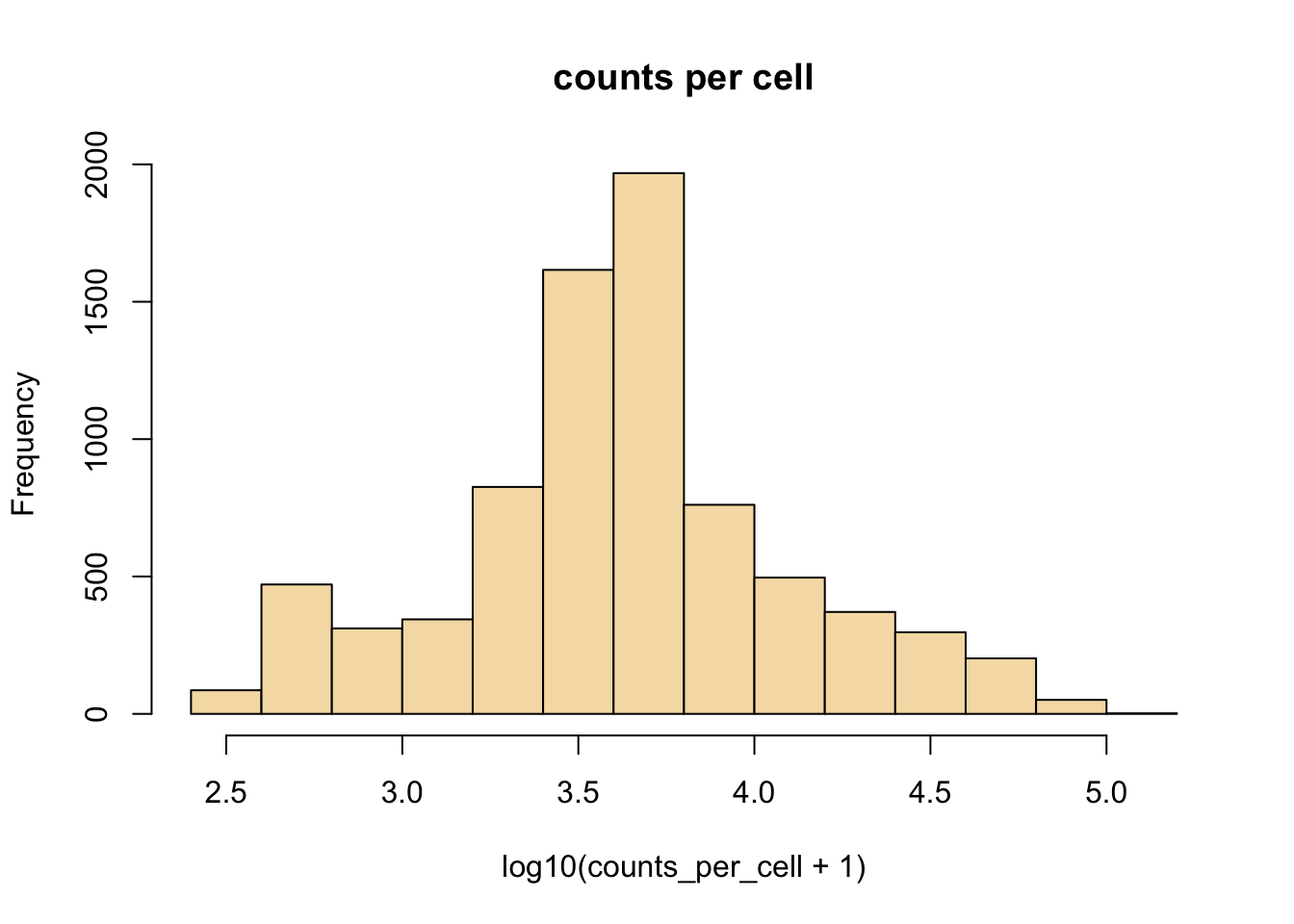
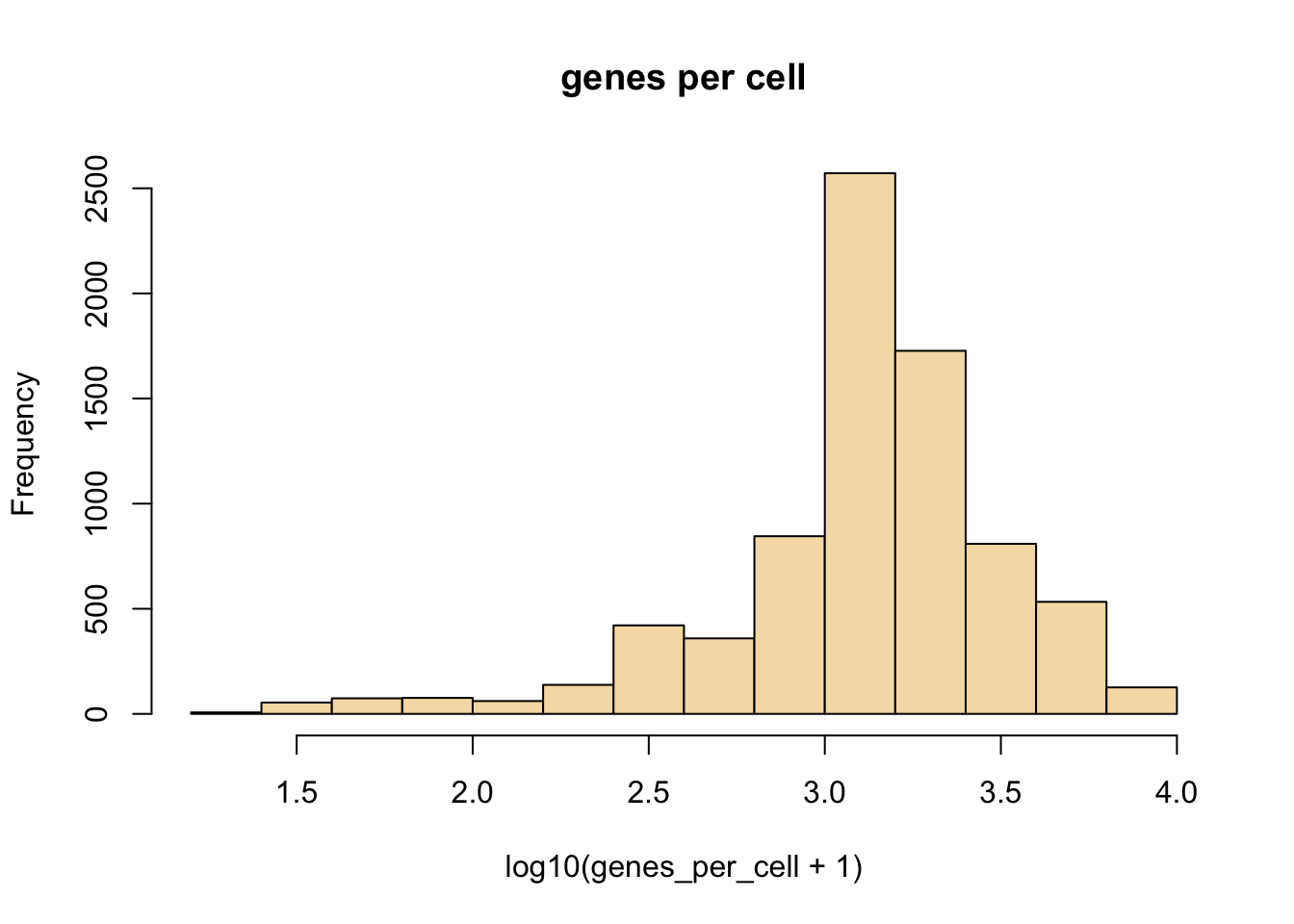
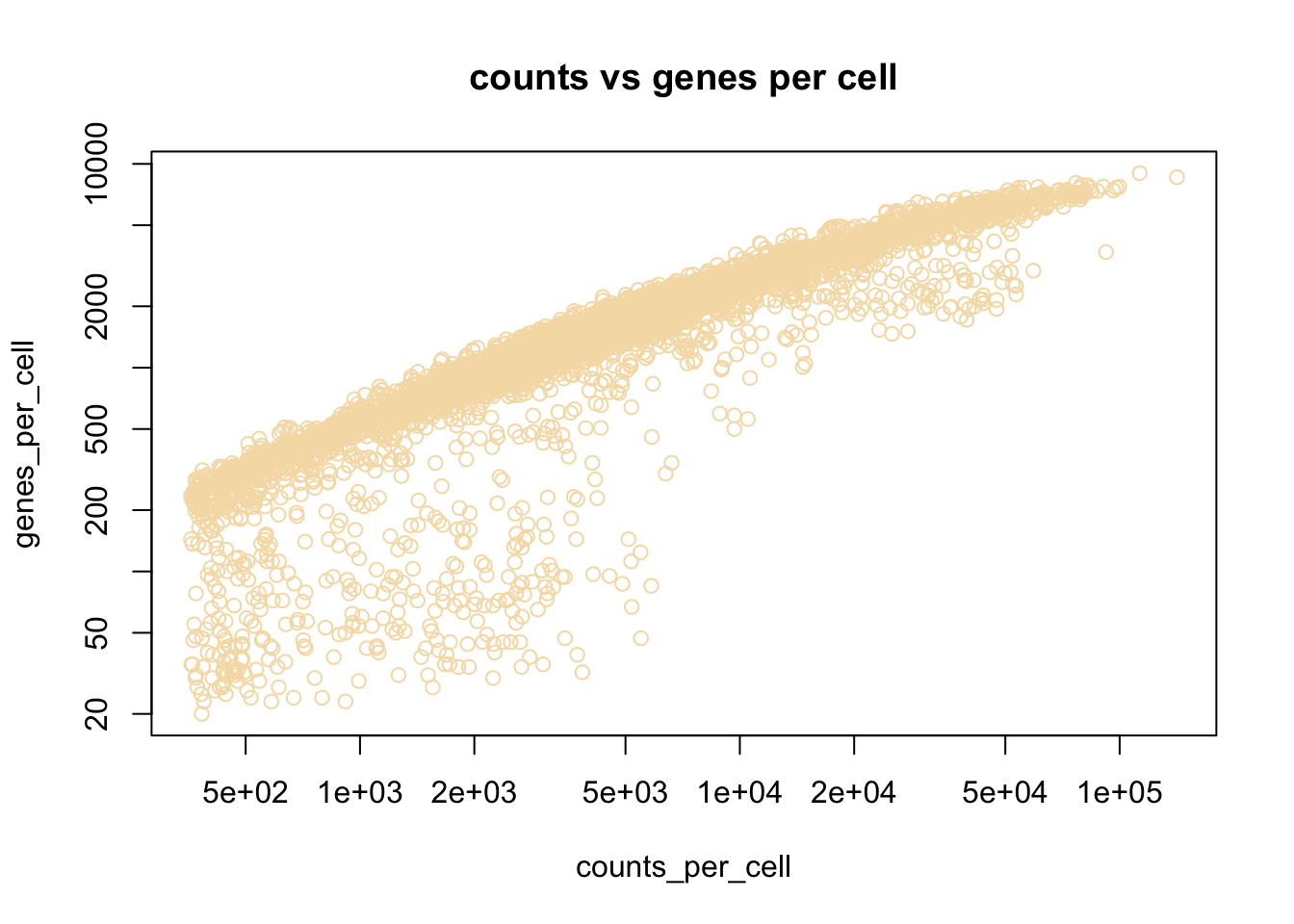
Here we see examples of plotting a new plot, the histogram. R makes this really easy with the hist function. We are also transforming the values to log10 before plotting, this is done with the log10 method. When logging count data, the + 1 is used to avoid log10(0) which is not defined.
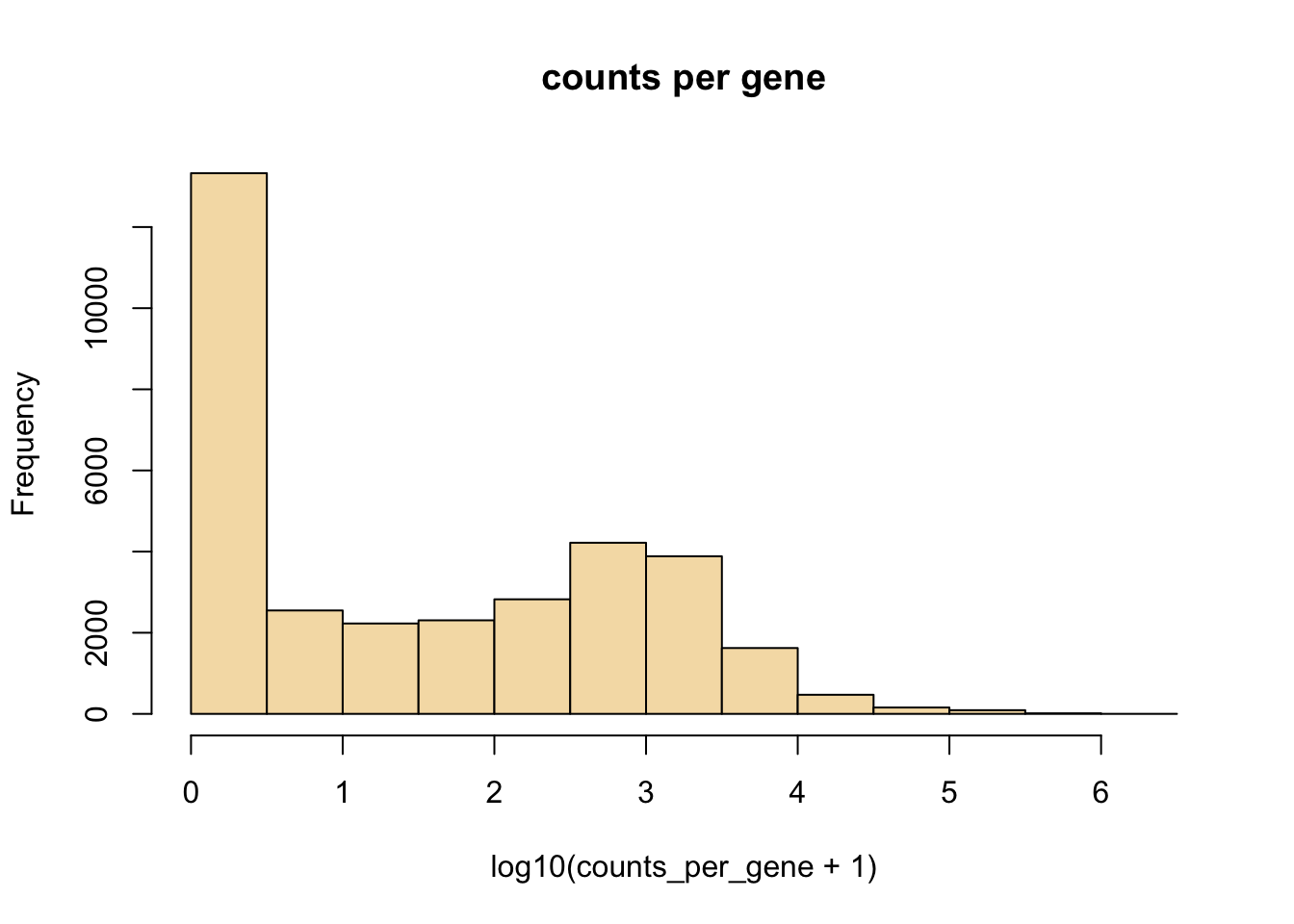
Can you make a histogram of counts per gene in log10 scale?
4.3.2 Plot cells ranked by their number of detected genes.
Here we rank each cell by its library complexity, ie the number of genes detected per cell. This is a very useful plot as it shows the distribution of library complexity in the sequencing run. One can use this plot to investigate observations (potential cells) that are actually failed libraries (lower end outliers) or observations that are cell doublets (higher end outliers).
![]()
4.4 Beginning with Seurat:
4.4.1 Creating a seurat object
To analyze our single cell data we will use a seurat object. Can you create an Seurat object with the 10x data and save it in an object called ‘seurat’? hint: CreateSeuratObject(). Can you include only genes that are are expressed in 3 or more cells and cells with complexity of 350 genes or more? How many genes are you left with? How many cells?
### seurat<-CreateSeuratObject(raw.data = counts, ? = 3, ? = 350, project = "10X_NSCLC")
seurat <- CreateSeuratObject(counts = counts, min.cells = 3, min.features = 350, project = "10X_NSCLC")## Warning: Feature names cannot have underscores ('_'), replacing
## with dashes ('-')4.4.1.1 Object Slots
Almost all our analysis will be on the single object, of class Seurat. This object contains various “slots” (designated by seurat@slotname) that will store not only the raw count data, but also the results from various computations below. This has the advantage that we do not need to keep track of inidividual variables of interest - they can all be collapsed into a single object as long as these slots are pre-defined as:
- assays - A list of assays within this object
- meta.data - Cell-level meta data
- active.assay - Name of active, or default, assay
- active.ident - Identity classes for the current object
- graphs - A list of nearest neighbor graphs
- reductions - A list of DimReduc objects
- project.name - User-defined project name (optional)
- tools - Empty list. Tool developers can store any internal data from their methods here
- misc - Empty slot. User can store additional information here version Seurat version used when creating the object
seurat@assays$RNA@counts is a slot that stores the original gene count matrix. We can view the first 10 rows (genes) and the first 10 columns (cells).
## 10 x 10 sparse Matrix of class "dgCMatrix"## [[ suppressing 10 column names 'AAACCTGAGCTAGTCT', 'AAACCTGAGGGCACTA', 'AAACCTGAGTACGTTC' ... ]]##
## FO538757.2 . . . . 1 2 . . . .
## AP006222.2 . . . . . . . . . .
## RP4-669L17.10 . . . . . . . . . .
## RP11-206L10.9 . . . . . . . . . .
## LINC00115 . . . . . . . . . .
## FAM41C . . . . . . . . . .
## SAMD11 . . . . . 1 . . . .
## NOC2L . . . . 2 4 . 1 . .
## KLHL17 . . . . . . . . . .
## PLEKHN1 . . . . . . . . . .4.4.1.2 Object Information
Summary information about Seurat objects can be had quickly and easily using standard R functions. Object shape/dimensions can be found using the dim, ncol, and nrow functions; cell and feature names can be found using the colnames and rownames functions, respectively, or the dimnames function. A vector of names of Assay, DimReduc, and Graph objects contained in a Seurat object can be had by using names.
The following examples use the PBMC 3k dataset
## An object of class Seurat
## 20213 features across 7109 samples within 1 assay
## Active assay: RNA (20213 features)# nrow and ncol provide the number of features and cells in the active assay, respectively
# dim provides both nrow and ncol at the same time
dim(x = seurat)## [1] 20213 7109# In addtion to rownames and colnames, one can use dimnames
# which provides a two-length list with both rownames and colnames
head(x = rownames(x = seurat))## [1] "FO538757.2" "AP006222.2" "RP4-669L17.10"
## [4] "RP11-206L10.9" "LINC00115" "FAM41C"## [1] "AAACCTGAGCTAGTCT" "AAACCTGAGGGCACTA" "AAACCTGAGTACGTTC"
## [4] "AAACCTGAGTCCGGTC" "AAACCTGCACCAGGTC" "AAACCTGCACCTCGTT"# A vector of names of associated objects can be had with the names function
# These can be passed to the double [[ extract operator to pull them from the Seurat object
names(x = seurat)## [1] "RNA"You can also see a print out of the entire structure of the object by using the str commmand.
## Formal class 'Seurat' [package "Seurat"] with 12 slots
## ..@ assays :List of 1
## .. ..$ RNA:Formal class 'Assay' [package "Seurat"] with 8 slots
## .. .. .. ..@ counts :Formal class 'dgCMatrix' [package "Matrix"] with 6 slots
## .. .. .. .. .. ..@ i : int [1:13732088] 22 37 100 102 105 132 146 171 177 185 ...
## .. .. .. .. .. ..@ p : int [1:7110] 0 1184 2571 4355 5447 8072 13674 15861 17504 18605 ...
## .. .. .. .. .. ..@ Dim : int [1:2] 20213 7109
## .. .. .. .. .. ..@ Dimnames:List of 2
## .. .. .. .. .. .. ..$ : chr [1:20213] "FO538757.2" "AP006222.2" "RP4-669L17.10" "RP11-206L10.9" ...
## .. .. .. .. .. .. ..$ : chr [1:7109] "AAACCTGAGCTAGTCT" "AAACCTGAGGGCACTA" "AAACCTGAGTACGTTC" "AAACCTGAGTCCGGTC" ...
## .. .. .. .. .. ..@ x : num [1:13732088] 1 2 7 1 1 3 1 1 1 1 ...
## .. .. .. .. .. ..@ factors : list()
## .. .. .. ..@ data :Formal class 'dgCMatrix' [package "Matrix"] with 6 slots
## .. .. .. .. .. ..@ i : int [1:13732088] 22 37 100 102 105 132 146 171 177 185 ...
## .. .. .. .. .. ..@ p : int [1:7110] 0 1184 2571 4355 5447 8072 13674 15861 17504 18605 ...
## .. .. .. .. .. ..@ Dim : int [1:2] 20213 7109
## .. .. .. .. .. ..@ Dimnames:List of 2
## .. .. .. .. .. .. ..$ : chr [1:20213] "FO538757.2" "AP006222.2" "RP4-669L17.10" "RP11-206L10.9" ...
## .. .. .. .. .. .. ..$ : chr [1:7109] "AAACCTGAGCTAGTCT" "AAACCTGAGGGCACTA" "AAACCTGAGTACGTTC" "AAACCTGAGTCCGGTC" ...
## .. .. .. .. .. ..@ x : num [1:13732088] 1 2 7 1 1 3 1 1 1 1 ...
## .. .. .. .. .. ..@ factors : list()
## .. .. .. ..@ scale.data : num[0 , 0 ]
## .. .. .. ..@ key : chr "rna_"
## .. .. .. ..@ assay.orig : NULL
## .. .. .. ..@ var.features : logi(0)
## .. .. .. ..@ meta.features:'data.frame': 20213 obs. of 0 variables
## .. .. .. ..@ misc : NULL
## ..@ meta.data :'data.frame': 7109 obs. of 3 variables:
## .. ..$ orig.ident : Factor w/ 1 level "10X_NSCLC": 1 1 1 1 1 1 1 1 1 1 ...
## .. ..$ nCount_RNA : num [1:7109] 3605 3828 6457 3075 9399 ...
## .. ..$ nFeature_RNA: int [1:7109] 1184 1387 1784 1092 2625 5602 2187 1643 1101 2717 ...
## ..@ active.assay: chr "RNA"
## ..@ active.ident: Factor w/ 1 level "10X_NSCLC": 1 1 1 1 1 1 1 1 1 1 ...
## .. ..- attr(*, "names")= chr [1:7109] "AAACCTGAGCTAGTCT" "AAACCTGAGGGCACTA" "AAACCTGAGTACGTTC" "AAACCTGAGTCCGGTC" ...
## ..@ graphs : list()
## ..@ neighbors : list()
## ..@ reductions : list()
## ..@ project.name: chr "10X_NSCLC"
## ..@ misc : list()
## ..@ version :Classes 'package_version', 'numeric_version' hidden list of 1
## .. ..$ : int [1:3] 3 1 2
## ..@ commands : list()
## ..@ tools : list()4.4.1.3 Data Access
Pulling specific Assay, DimReduc, or Graph objects can be done with the double [[ extract operator. Adding new objects to a Seurat object is also done with the double [[ extract operator; Seurat will figure out where in the Seurat object a new associated object belongs.
## Assay data with 20213 features for 7109 cells
## First 10 features:
## FO538757.2, AP006222.2, RP4-669L17.10, RP11-206L10.9,
## LINC00115, FAM41C, SAMD11, NOC2L, KLHL17, PLEKHN1Accessing data from an Seurat object is done with the GetAssayData function. Adding expression data to either the counts, data, or scale.data slots can be done with SetAssayData. New data must have the same cells in the same order as the current expression data. Data added to counts or data must have the same features as the current expression data.
## 10 x 10 sparse Matrix of class "dgCMatrix"## [[ suppressing 10 column names 'AAACCTGAGCTAGTCT', 'AAACCTGAGGGCACTA', 'AAACCTGAGTACGTTC' ... ]]##
## FO538757.2 . . . . 1 2 . . . .
## AP006222.2 . . . . . . . . . .
## RP4-669L17.10 . . . . . . . . . .
## RP11-206L10.9 . . . . . . . . . .
## LINC00115 . . . . . . . . . .
## FAM41C . . . . . . . . . .
## SAMD11 . . . . . 1 . . . .
## NOC2L . . . . 2 4 . 1 . .
## KLHL17 . . . . . . . . . .
## PLEKHN1 . . . . . . . . . .Cell-level meta data can be accessed with the single [ extract operator or using the $ sign. Pulling with the $ sign means only one bit of meta data can be pulled at a time, though tab-autocompletion has been enabled for it, making it ideal for interactive use. Adding cell-level meta data can be set using the single [ extract operator as well, or by using AddMetaData.
# Cell-level meta data is stored as a data frame
# Standard data frame functions work on the meta data data frame
colnames(x = seurat[])## [1] "AAACCTGAGCTAGTCT" "AAACCTGAGGGCACTA" "AAACCTGAGTACGTTC"
## [4] "AAACCTGAGTCCGGTC" "AAACCTGCACCAGGTC" "AAACCTGCACCTCGTT"
## [7] "AAACCTGCAGCTGTGC" "AAACCTGGTAAATGAC" "AAACCTGGTACTTAGC"
## [10] "AAACCTGTCCTCAATT" "AAACCTGTCCTGCAGG" "AAACGGGAGCTTATCG"
## [13] "AAACGGGAGGCCCTTG" "AAACGGGCAAGTAATG" "AAACGGGCACCAGATT"
## [16] "AAACGGGGTAATCACC" "AAACGGGGTAGCTGCC" "AAACGGGGTGGTGTAG"
## [19] "AAACGGGTCACCTCGT" "AAACGGGTCCCAAGTA" "AAAGATGAGAAACCTA"
## [22] "AAAGATGAGACTTTCG" "AAAGATGAGATATGGT" "AAAGATGAGATCCGAG"
## [25] "AAAGATGAGATGAGAG" "AAAGATGAGCCAGTAG" "AAAGATGCAATCCAAC"
## [28] "AAAGATGCACGAAATA" "AAAGATGCACGTAAGG" "AAAGATGCAGAGTGTG"
## [31] "AAAGATGCAGCCAGAA" "AAAGATGCAGGACCCT" "AAAGATGGTCATACTG"
## [34] "AAAGATGGTCCGTGAC" "AAAGATGGTCGAAAGC" "AAAGATGGTGCCTGGT"
## [37] "AAAGATGGTTACCGAT" "AAAGATGGTTGGTAAA" "AAAGATGTCAGCGATT"
## [40] "AAAGATGTCCCAAGTA" "AAAGATGTCCGAATGT" "AAAGATGTCCTAGTGA"
## [43] "AAAGATGTCGAACTGT" "AAAGATGTCTGTCTCG" "AAAGCAAAGAATTGTG"
## [46] "AAAGCAAAGAGACGAA" "AAAGCAAAGAGTTGGC" "AAAGCAACAAGGTTCT"
## [49] "AAAGCAACACGCCAGT" "AAAGCAAGTAGCTGCC" "AAAGCAAGTGCCTGTG"
## [52] "AAAGCAAGTTAGTGGG" "AAAGCAATCACTATTC" "AAAGCAATCATCGGAT"
## [55] "AAAGCAATCATCTGCC" "AAAGCAATCCTAGAAC" "AAAGCAATCGAACGGA"
## [58] "AAAGCAATCGTACGGC" "AAAGCAATCTCAAGTG" "AAAGTAGAGAGTAATC"
## [61] "AAAGTAGAGCCGATTT" "AAAGTAGAGGATTCGG" "AAAGTAGCAATGTAAG"
## [64] "AAAGTAGCACGACTCG" "AAAGTAGGTAATTGGA" "AAAGTAGGTATCAGTC"
## [67] "AAAGTAGGTCGCGAAA" "AAAGTAGGTGGTCCGT" "AAAGTAGGTTGCCTCT"
## [70] "AAAGTAGTCAGGCAAG" "AAAGTAGTCCAAAGTC" "AAAGTAGTCTTGTCAT"
## [73] "AAATGCCAGACGACGT" "AAATGCCAGGCAAAGA" "AAATGCCAGGGTGTTG"
## [76] "AAATGCCAGGTAAACT" "AAATGCCCAATGTAAG" "AAATGCCCACACATGT"
## [79] "AAATGCCCAGCTCGAC" "AAATGCCCATCTATGG" "AAATGCCGTACTTCTT"
## [82] "AAATGCCGTCTTGCGG" "AAATGCCGTGTAACGG" "AAATGCCTCCAAACAC"
## [85] "AAATGCCTCCGCGGTA" "AAATGCCTCGTCGTTC" "AACACGTAGCTAGTCT"
## [88] "AACACGTAGGATTCGG" "AACACGTAGTACCGGA" "AACACGTCACAGAGGT"
## [91] "AACACGTCACGACTCG" "AACACGTCAGTCAGCC" "AACACGTGTAATCGTC"
## [94] "AACACGTGTACCAGTT" "AACACGTGTTGGGACA" "AACACGTTCACCACCT"
## [97] "AACACGTTCACCGGGT" "AACACGTTCCAGAGGA" "AACACGTTCCTGCAGG"
## [100] "AACACGTTCGCATGGC" "AACACGTTCTTACCGC" "AACACGTTCTTGCATT"
## [103] "AACCATGAGTAGTGCG" "AACCATGCAAAGGCGT" "AACCATGCAAGCGAGT"
## [106] "AACCATGCAGCATACT" "AACCATGCATGTTGAC" "AACCATGCATTCTCAT"
## [109] "AACCATGGTCCGAAGA" "AACCATGGTGCCTGCA" "AACCATGGTGTTGAGG"
## [112] "AACCATGGTTGATTCG" "AACCATGTCAATCTCT" "AACCATGTCCGAAGAG"
## [115] "AACCATGTCTCCGGTT" "AACCGCGAGAGGTTGC" "AACCGCGAGGGTCTCC"
## [118] "AACCGCGCAAGGTGTG" "AACCGCGCAGGACGTA" "AACCGCGCAGGGTTAG"
## [121] "AACCGCGCAGTAACGG" "AACCGCGCATTCCTGC" "AACCGCGGTGACTCAT"
## [124] "AACCGCGGTGGGTCAA" "AACCGCGTCAATCTCT" "AACCGCGTCCTTGGTC"
## [127] "AACCGCGTCGCACTCT" "AACCGCGTCGGCCGAT" "AACCGCGTCTTGCCGT"
## [130] "AACGTTGAGAACTCGG" "AACGTTGAGGGTGTGT" "AACGTTGCAGGTCGTC"
## [133] "AACGTTGCAGTCGTGC" "AACGTTGCATATACGC" "AACGTTGTCATACGGT"
## [136] "AACGTTGTCCACGACG" "AACGTTGTCCGTCATC" "AACGTTGTCTGGTATG"
## [139] "AACTCAGAGACTAAGT" "AACTCAGAGCGTAATA" "AACTCAGAGCGTCTAT"
## [142] "AACTCAGAGCTGAAAT" "AACTCAGAGTGGACGT" "AACTCAGCACATAACC"
## [145] "AACTCAGGTGTTCGAT" "AACTCAGGTTCTCATT" "AACTCAGTCACCCTCA"
## [148] "AACTCAGTCAGCCTAA" "AACTCAGTCCTATGTT" "AACTCAGTCTAACCGA"
## [151] "AACTCAGTCTCGTATT" "AACTCCCAGACAAGCC" "AACTCCCAGACTAGGC"
## [154] "AACTCCCAGGATCGCA" "AACTCCCAGGCAGGTT" "AACTCCCAGTACGTTC"
## [157] "AACTCCCAGTCGTTTG" "AACTCCCAGTGACTCT" "AACTCCCCACAAGTAA"
## [160] "AACTCCCCACGCATCG" "AACTCCCCAGTATCTG" "AACTCCCCATCCTAGA"
## [163] "AACTCCCCATCGTCGG" "AACTCCCGTCGAACAG" "AACTCCCGTGCACGAA"
## [166] "AACTCCCGTTCACCTC" "AACTCCCTCAGTTTGG" "AACTCCCTCTGGTGTA"
## [169] "AACTCTTCAAGAAGAG" "AACTCTTCAAGTCTGT" "AACTCTTCAATGTTGC"
## [172] "AACTCTTCATCTCCCA" "AACTCTTCATTTCAGG" "AACTCTTGTGCGGTAA"
## [175] "AACTCTTGTGTCCTCT" "AACTCTTGTTTGGGCC" "AACTCTTTCAACGAAA"
## [178] "AACTCTTTCCTTGCCA" "AACTCTTTCTCGTTTA" "AACTGGTAGAGGTACC"
## [181] "AACTGGTAGGGAAACA" "AACTGGTAGGTGTGGT" "AACTGGTAGTACGACG"
## [184] "AACTGGTCAAACTGCT" "AACTGGTCACGAGGTA" "AACTGGTGTACATGTC"
## [187] "AACTGGTGTGGCAAAC" "AACTGGTGTTACCAGT" "AACTGGTGTTGAGGTG"
## [190] "AACTGGTGTTGGAGGT" "AACTGGTGTTTGACAC" "AACTGGTGTTTGTTTC"
## [193] "AACTGGTTCAATCACG" "AACTGGTTCACAAACC" "AACTGGTTCACCCGAG"
## [196] "AACTGGTTCAGCACAT" "AACTGGTTCCTTTACA" "AACTGGTTCGGGAGTA"
## [199] "AACTGGTTCGTCACGG" "AACTGGTTCTCTTATG" "AACTTTCAGGCAGTCA"
## [202] "AACTTTCAGGTTACCT" "AACTTTCCACCAGGCT" "AACTTTCCAGGTGCCT"
## [205] "AACTTTCCATGAACCT" "AACTTTCCATGTAAGA" "AACTTTCCATGTCCTC"
## [208] "AACTTTCGTAAGTGTA" "AACTTTCGTACACCGC" "AACTTTCGTATAGGTA"
## [211] "AACTTTCGTCTAGTCA" "AACTTTCGTTAAAGAC" "AACTTTCGTTACGGAG"
## [214] "AACTTTCGTTGTGGAG" "AACTTTCTCACTCCTG" "AACTTTCTCGAACTGT"
## [217] "AACTTTCTCGCAAACT" "AACTTTCTCTTGCAAG" "AAGACCTAGAGGTAGA"
## [220] "AAGACCTAGGATATAC" "AAGACCTAGGCTATCT" "AAGACCTAGTCCAGGA"
## [223] "AAGACCTAGTCGTTTG" "AAGACCTAGTGACATA" "AAGACCTCAAGCCTAT"
## [226] "AAGACCTCAATGAATG" "AAGACCTCATACAGCT" "AAGACCTCATGGGAAC"
## [229] "AAGACCTCATTTGCCC" "AAGACCTGTAATAGCA" "AAGACCTGTAGCTAAA"
## [232] "AAGACCTGTCCGAGTC" "AAGACCTGTCTAGAGG" "AAGACCTGTGAAAGAG"
## [235] "AAGACCTGTTGACGTT" "AAGACCTTCACCGTAA" "AAGACCTTCCGGCACA"
## [238] "AAGACCTTCTCCAGGG" "AAGCCGCAGAGTCGGT" "AAGCCGCAGCACGCCT"
## [241] "AAGCCGCAGCCAGGAT" "AAGCCGCAGCTGCGAA" "AAGCCGCCACGACGAA"
## [244] "AAGCCGCCATGGTTGT" "AAGCCGCCATTCCTCG" "AAGCCGCGTACGCACC"
## [247] "AAGCCGCGTCCTCCAT" "AAGCCGCGTTACCAGT" "AAGCCGCGTTGACGTT"
## [250] "AAGCCGCTCATGCAAC" "AAGCCGCTCCAGAGGA" "AAGCCGCTCCTATTCA"
## [253] "AAGCCGCTCCTCCTAG" "AAGCCGCTCGGATGGA" "AAGCCGCTCGTAGGAG"
## [256] "AAGCCGCTCTAACTGG" "AAGGAGCAGATGGCGT" "AAGGAGCAGCCCAATT"
## [259] "AAGGAGCAGCGGCTTC" "AAGGAGCAGGATATAC" "AAGGAGCAGTAACCCT"
## [262] "AAGGAGCCAGACGCTC" "AAGGAGCCAGACGTAG" "AAGGAGCCAGCCTATA"
## [265] "AAGGAGCGTCTCAACA" "AAGGAGCTCAATCACG" "AAGGAGCTCAGGCAAG"
## [268] "AAGGAGCTCGGAAACG" "AAGGAGCTCTAGCACA" "AAGGAGCTCTCAAACG"
## [271] "AAGGAGCTCTTGAGAC" "AAGGCAGAGGATGGAA" "AAGGCAGAGTGACATA"
## [274] "AAGGCAGCAAGTAATG" "AAGGCAGCACACATGT" "AAGGCAGCACGAGGTA"
## [277] "AAGGCAGCATACTACG" "AAGGCAGCATCAGTAC" "AAGGCAGCATTCACTT"
## [280] "AAGGCAGGTAGCCTAT" "AAGGCAGGTGATGTGG" "AAGGCAGGTGTTTGGT"
## [283] "AAGGCAGGTTGTGGCC" "AAGGCAGTCAATAAGG" "AAGGCAGTCTGCTGTC"
## [286] "AAGGTTCAGAACAATC" "AAGGTTCAGAATCTCC" "AAGGTTCAGCGTTGCC"
## [289] "AAGGTTCAGGCCGAAT" "AAGGTTCAGGCTATCT" "AAGGTTCAGGGTGTGT"
## [292] "AAGGTTCAGTCAAGCG" "AAGGTTCAGTTACCCA" "AAGGTTCCAACACCCG"
## [295] "AAGGTTCCACAGCGTC" "AAGGTTCCACTAAGTC" "AAGGTTCCACTTGGAT"
## [298] "AAGGTTCCATAAGACA" "AAGGTTCCATCACAAC" "AAGGTTCCATCGGACC"
## [301] "AAGGTTCGTATAGTAG" "AAGGTTCGTGATGATA" "AAGGTTCGTTATGCGT"
## [304] "AAGGTTCGTTCCGGCA" "AAGGTTCTCCCTTGTG" "AAGTCTGAGATGTGGC"
## [307] "AAGTCTGAGGATCGCA" "AAGTCTGCAAGCCGCT" "AAGTCTGGTTCCTCCA"
## [310] "AAGTCTGTCAACCATG" "AAGTCTGTCATAGCAC" "AAGTCTGTCCAAGCCG"
## [313] "AAGTCTGTCTAACTTC" "AATCCAGAGCTGATAA" "AATCCAGAGGCTCAGA"
## [316] "AATCCAGAGGGATCTG" "AATCCAGAGGTGTTAA" "AATCCAGCACATCTTT"
## [319] "AATCCAGCACGAAACG" "AATCCAGCACGGATAG" "AATCCAGCAGACGCTC"
## [322] "AATCCAGGTCAGAGGT" "AATCCAGGTCGGCTCA" "AATCCAGGTTCCCGAG"
## [325] "AATCCAGGTTCGGGCT" "AATCCAGGTTGGTGGA" "AATCCAGTCAGAGCTT"
## [328] "AATCCAGTCCATTCTA" "AATCCAGTCCTGCAGG" "AATCGGTAGCCACGTC"
## [331] "AATCGGTAGGGATACC" "AATCGGTCAACGCACC" "AATCGGTCACCATCCT"
## [334] "AATCGGTCAGCGAACA" "AATCGGTCATGTCCTC" "AATCGGTCATTATCTC"
## [337] "AATCGGTGTCGGATCC" "AATCGGTGTCTGGTCG" "AATCGGTGTTTGCATG"
## [340] "AATCGGTTCAAACGGG" "AATCGGTTCAACGCTA" "AATCGGTTCCACGCAG"
## [343] "AATCGGTTCCCGGATG" "AATCGGTTCGTGGACC" "AATCGGTTCTACCAGA"
## [346] "AATCGGTTCTAGCACA" "ACACCAAAGCGATATA" "ACACCAAAGCTCCCAG"
## [349] "ACACCAAAGTGGTAGC" "ACACCAAAGTGTCCAT" "ACACCAACAAGTCATC"
## [352] "ACACCAACACACGCTG" "ACACCAACACAGCCCA" "ACACCAACAGGTCTCG"
## [355] "ACACCAACATCGGAAG" "ACACCAAGTCAAACTC" "ACACCAAGTCGGCTCA"
## [358] "ACACCAAGTCTGGTCG" "ACACCAAGTGACAAAT" "ACACCAAGTGCTTCTC"
## [361] "ACACCAAGTGGACGAT" "ACACCAATCATCGGAT" "ACACCAATCCGTAGTA"
## [364] "ACACCAATCGTCTGAA" "ACACCAATCGTTGCCT" "ACACCCTAGACCTAGG"
## [367] "ACACCCTAGCCAGTAG" "ACACCCTAGTAGCGGT" "ACACCCTCAACTGCTA"
## [370] "ACACCCTCAGCCAGAA" "ACACCCTCATCGGTTA" "ACACCCTCATGCCACG"
## [373] "ACACCCTCATGTCGAT" "ACACCCTCATTATCTC" "ACACCCTGTAGGACAC"
## [376] "ACACCCTTCAAACAAG" "ACACCCTTCATATCGG" "ACACCCTTCATTATCC"
## [379] "ACACCCTTCCAGGGCT" "ACACCCTTCCCTAATT" "ACACCCTTCCGTTGCT"
## [382] "ACACCCTTCGCGCCAA" "ACACCCTTCGTAGGTT" "ACACCCTTCGTTACGA"
## [385] "ACACCCTTCTGGGCCA" "ACACCGGAGAGCTATA" "ACACCGGAGCACCGCT"
## [388] "ACACCGGAGGCATGGT" "ACACCGGAGGCTATCT" "ACACCGGAGTCATCCA"
## [391] "ACACCGGAGTGAAGAG" "ACACCGGAGTGGGATC" "ACACCGGCAAGCCGTC"
## [394] "ACACCGGCAGGTCTCG" "ACACCGGGTGACTACT" "ACACCGGGTTCGCTAA"
## [397] "ACACCGGTCGCCTGTT" "ACACCGGTCTTAGAGC" "ACACTGAAGACAGACC"
## [400] "ACACTGAAGTACTTGC" "ACACTGAAGTCTTGCA" "ACACTGACAACTGCGC"
## [403] "ACACTGACAAGAGGCT" "ACACTGACAAGCCGCT" "ACACTGACACCCAGTG"
## [406] "ACACTGACACTCAGGC" "ACACTGAGTACACCGC" "ACACTGAGTAGGGTAC"
## [409] "ACACTGAGTCGCATAT" "ACACTGAGTCTCTCTG" "ACACTGAGTGGCAAAC"
## [412] "ACACTGAGTGTCCTCT" "ACACTGAGTTGAGTTC" "ACACTGATCAGTGCAT"
## [415] "ACAGCCGAGACCACGA" "ACAGCCGAGACTAGGC" "ACAGCCGAGCTACCGC"
## [418] "ACAGCCGAGTTCGCGC" "ACAGCCGCAACGATCT" "ACAGCCGCACCAGGTC"
## [421] "ACAGCCGCACCATCCT" "ACAGCCGCATGGGACA" "ACAGCCGGTACCGGCT"
## [424] "ACAGCCGGTAGCGTAG" "ACAGCCGGTTCAGGCC" "ACAGCCGGTTCCACTC"
## [427] "ACAGCCGGTTTCGCTC" "ACAGCCGTCAGGCCCA" "ACAGCCGTCCCATTAT"
## [430] "ACAGCCGTCGTGGACC" "ACAGCCGTCTGATTCT" "ACAGCTAAGATGGCGT"
## [433] "ACAGCTAAGCGTAGTG" "ACAGCTACAATAGCAA" "ACAGCTATCACATGCA"
## [436] "ACAGCTATCCAACCAA" "ACAGCTATCGTAGGAG" "ACAGCTATCTCGGACG"
## [439] "ACATACGAGAATTGTG" "ACATACGAGAGTCTGG" "ACATACGCAAGCCGTC"
## [442] "ACATACGCAGACGTAG" "ACATACGCATCGGACC" "ACATACGGTCATTAGC"
## [445] "ACATACGGTCGGCACT" "ACATACGGTCTAGTCA" "ACATACGTCATGCTCC"
## [448] "ACATCAGAGTCCCACG" "ACATCAGAGTTATCGC" "ACATCAGCACACCGCA"
## [451] "ACATCAGCACAGTCGC" "ACATCAGCACGCGAAA" "ACATCAGCATCCCACT"
## [454] "ACATCAGCATTCTTAC" "ACATCAGCATTTGCTT" "ACATCAGGTCGAACAG"
## [457] "ACATCAGGTCTCGTTC" "ACATCAGGTGAAAGAG" "ACATCAGGTGCATCTA"
## [460] "ACATCAGTCACCGTAA" "ACATCAGTCAGTCAGT" "ACATCAGTCGAACGGA"
## [463] "ACATCAGTCGACAGCC" "ACATCAGTCGCACTCT" "ACATCAGTCTTTACGT"
## [466] "ACATGGTAGACTTGAA" "ACATGGTAGTAGTGCG" "ACATGGTCAAAGCGGT"
## [469] "ACATGGTCAATAAGCA" "ACATGGTCAATGAATG" "ACATGGTCATGCAATC"
## [472] "ACATGGTCATGGTCAT" "ACATGGTGTGTGCCTG" "ACATGGTGTTGATTCG"
## [475] "ACATGGTTCAATCTCT" "ACATGGTTCCGCGTTT" "ACATGGTTCCTAAGTG"
## [478] "ACATGGTTCGTACGGC" "ACATGGTTCGTTTATC" "ACATGGTTCTACTATC"
## [481] "ACATGGTTCTGCCAGG" "ACCAGTAAGAGAGCTC" "ACCAGTACACGGTGTC"
## [484] "ACCAGTACATGCAATC" "ACCAGTAGTCTCTCGT" "ACCAGTAGTGCCTGCA"
## [487] "ACCAGTAGTTCCCGAG" "ACCAGTAGTTTGGCGC" "ACCAGTATCCAATGGT"
## [490] "ACCAGTATCCATGAAC" "ACCCACTAGAATTCCC" "ACCCACTAGCGGATCA"
## [493] "ACCCACTAGCTCCTCT" "ACCCACTAGGCTCATT" "ACCCACTCAAAGCAAT"
## [496] "ACCCACTCAACACCCG" "ACCCACTCAGATCGGA" "ACCCACTCATGGTAGG"
## [499] "ACCCACTGTCATTAGC" "ACCCACTGTCCTCTTG" "ACCCACTGTCTCTTAT"
## [502] "ACCCACTGTGGCAAAC" "ACCCACTGTTCCGGCA" "ACCCACTGTTGTTTGG"
## [505] "ACCCACTTCCTTGACC" "ACCCACTTCGGTGTTA" "ACCGTAAAGAGTGAGA"
## [508] "ACCGTAAAGGTAAACT" "ACCGTAACACACGCTG" "ACCGTAACAGCTCGAC"
## [511] "ACCGTAACAGCTGTAT" "ACCGTAACATCCTAGA" "ACCGTAACATGGGAAC"
## [514] "ACCGTAACATTTCAGG" "ACCGTAAGTTCGCGAC" "ACCGTAATCCTATGTT"
## [517] "ACCGTAATCGGTGTTA" "ACCGTAATCGTCACGG" "ACCGTAATCTGGCGTG"
## [520] "ACCTTTAAGAGCTTCT" "ACCTTTAAGTTGTCGT" "ACCTTTACAAGCCCAC"
## [523] "ACCTTTACATGTCCTC" "ACCTTTAGTAGAGTGC" "ACCTTTATCATCTGTT"
## [526] "ACCTTTATCCCTCTTT" "ACCTTTATCCCTGACT" "ACCTTTATCCTGTAGA"
## [529] "ACCTTTATCGCCAGCA" "ACCTTTATCTGCCCTA" "ACCTTTATCTTGACGA"
## [532] "ACGAGCCAGAGCCTAG" "ACGAGCCAGGTGATAT" "ACGAGCCCAAGCCGCT"
## [535] "ACGAGCCCAGGCAGTA" "ACGAGCCGTACCGCTG" "ACGAGCCGTAGAAAGG"
## [538] "ACGAGCCGTTGTCGCG" "ACGAGCCGTTTCGCTC" "ACGAGCCTCACTTCAT"
## [541] "ACGAGCCTCCGTAGGC" "ACGAGCCTCGTCTGAA" "ACGAGCCTCGTGGACC"
## [544] "ACGAGCCTCTTCATGT" "ACGAGGAAGAAGAAGC" "ACGAGGAAGGTGATTA"
## [547] "ACGAGGACACATAACC" "ACGAGGACATGGATGG" "ACGAGGAGTTATCACG"
## [550] "ACGAGGAGTTCGTTGA" "ACGAGGATCCAGGGCT" "ACGAGGATCCCTGACT"
## [553] "ACGAGGATCGAACTGT" "ACGATACAGAAAGTGG" "ACGATACAGACCTAGG"
## [556] "ACGATACAGACTAGAT" "ACGATACCAAACAACA" "ACGATACCAAGCTGGA"
## [559] "ACGATACCACAGGCCT" "ACGATACCAGCCTATA" "ACGATACGTATATCCG"
## [562] "ACGATACGTCAATACC" "ACGATACGTCTTCTCG" "ACGATACGTGCCTTGG"
## [565] "ACGATACGTGCGATAG" "ACGATACGTGGAAAGA" "ACGATACGTTCCAACA"
## [568] "ACGATACTCACATGCA" "ACGATACTCAGCGATT" "ACGATACTCCCAGGTG"
## [571] "ACGATGTAGAGGTACC" "ACGATGTAGATATGCA" "ACGATGTCAAGCGTAG"
## [574] "ACGATGTCAATAGCAA" "ACGATGTCACCAACCG" "ACGATGTCAGGAACGT"
## [577] "ACGATGTCATGTCGAT" "ACGATGTGTAGTAGTA" "ACGATGTGTGACTACT"
## [580] "ACGATGTGTGCACTTA" "ACGATGTGTGCCTGGT" "ACGATGTGTGGTACAG"
## [583] "ACGATGTGTTCAGGCC" "ACGATGTTCCACGAAT" "ACGATGTTCGGTCTAA"
## [586] "ACGATGTTCGTCCGTT" "ACGATGTTCGTTTATC" "ACGATGTTCTCGCTTG"
## [589] "ACGATGTTCTGACCTC" "ACGATGTTCTGTCAAG" "ACGATGTTCTTACCGC"
## [592] "ACGCAGCAGATCTGAA" "ACGCAGCAGATGTGGC" "ACGCAGCAGTGTCTCA"
## [595] "ACGCAGCCAACGATGG" "ACGCAGCCACACGCTG" "ACGCAGCCAGCTGTTA"
## [598] "ACGCAGCCAGGGTTAG" "ACGCAGCGTACTCAAC" "ACGCAGCGTAGGAGTC"
## [601] "ACGCAGCGTATATCCG" "ACGCAGCGTCACCTAA" "ACGCAGCGTCCTCCAT"
## [604] "ACGCAGCGTCTTCTCG" "ACGCAGCGTGTGGTTT" "ACGCAGCGTTCCTCCA"
## [607] "ACGCAGCGTTGTCTTT" "ACGCAGCTCAGGATCT" "ACGCAGCTCGACGGAA"
## [610] "ACGCAGCTCGCCAAAT" "ACGCAGCTCTGATACG" "ACGCCAGAGAACAACT"
## [613] "ACGCCAGAGATGGGTC" "ACGCCAGAGATGTAAC" "ACGCCAGAGCACACAG"
## [616] "ACGCCAGAGGATGTAT" "ACGCCAGAGTAGGTGC" "ACGCCAGAGTCAAGCG"
## [619] "ACGCCAGAGTCTCAAC" "ACGCCAGCAATGCCAT" "ACGCCAGCACACCGCA"
## [622] "ACGCCAGCACGTGAGA" "ACGCCAGCAGCGTCCA" "ACGCCAGGTCAATGTC"
## [625] "ACGCCAGGTCCGAGTC" "ACGCCAGGTCGACTAT" "ACGCCAGGTTCGCTAA"
## [628] "ACGCCAGTCACTCCTG" "ACGCCAGTCAGAGCTT" "ACGCCAGTCATATCGG"
## [631] "ACGCCAGTCCCACTTG" "ACGCCAGTCCTGCCAT" "ACGCCAGTCCTTTCGG"
## [634] "ACGCCAGTCGCAGGCT" "ACGCCAGTCGTTTATC" "ACGCCGAAGACTAGGC"
## [637] "ACGCCGAAGAGGTTAT" "ACGCCGAAGTGTTAGA" "ACGCCGAAGTTACGGG"
## [640] "ACGCCGACAATGTAAG" "ACGCCGACAGACGCCT" "ACGCCGACAGGTTTCA"
## [643] "ACGCCGACATCGGTTA" "ACGCCGAGTCTAACGT" "ACGCCGAGTCTCTTTA"
## [646] "ACGCCGAGTCTTCTCG" "ACGCCGAGTGTAATGA" "ACGCCGAGTTGCGCAC"
## [649] "ACGCCGATCAGGTAAA" "ACGCCGATCATGGTCA" "ACGCCGATCCTACAGA"
## [652] "ACGCCGATCTCGATGA" "ACGCCGATCTTAGAGC" "ACGCCGATCTTCAACT"
## [655] "ACGGAGAAGAGGACGG" "ACGGAGAAGTTCGCGC" "ACGGAGACAAGTTAAG"
## [658] "ACGGAGACAAGTTCTG" "ACGGAGACAATCTACG" "ACGGAGACAGACTCGC"
## [661] "ACGGAGAGTACACCGC" "ACGGAGAGTACTTGAC" "ACGGAGAGTGCTCTTC"
## [664] "ACGGAGAGTGGGTCAA" "ACGGAGAGTGTGACGA" "ACGGAGAGTTCCCGAG"
## [667] "ACGGAGAGTTCGGCAC" "ACGGAGATCAAACAAG" "ACGGAGATCACATACG"
## [670] "ACGGAGATCAGCGACC" "ACGGAGATCATCTGCC" "ACGGAGATCGAACGGA"
## [673] "ACGGCCAAGACCTAGG" "ACGGCCAAGCGAAGGG" "ACGGCCAAGCTGAAAT"
## [676] "ACGGCCAAGGATCGCA" "ACGGCCACAACGATCT" "ACGGCCACACACTGCG"
## [679] "ACGGCCACACGAGAGT" "ACGGCCACACGGATAG" "ACGGCCACACTCTGTC"
## [682] "ACGGCCACAGTAAGAT" "ACGGCCAGTCAACATC" "ACGGCCAGTGAGTGAC"
## [685] "ACGGCCATCACTTATC" "ACGGCCATCATAAAGG" "ACGGCCATCCAAAGTC"
## [688] "ACGGCCATCCGAGCCA" "ACGGCCATCGGAATCT" "ACGGCCATCGTCACGG"
## [691] "ACGGCCATCTGCCCTA" "ACGGGCTAGCCCAACC" "ACGGGCTAGGGTATCG"
## [694] "ACGGGCTAGGGTGTTG" "ACGGGCTCACACCGAC" "ACGGGCTCACCCATTC"
## [697] "ACGGGCTCATGTAGTC" "ACGGGCTCATGTCGAT" "ACGGGCTGTTCAACCA"
## [700] "ACGGGCTTCAACCAAC" "ACGGGCTTCAACCATG" "ACGGGCTTCTCTTGAT"
## [703] "ACGGGTCAGATGCCAG" "ACGGGTCAGCACACAG" "ACGGGTCCAGCTGTGC"
## [706] "ACGGGTCGTATAGGTA" "ACGGGTCGTTGGAGGT" "ACGGGTCTCATGCATG"
## [709] "ACGGGTCTCATGGTCA" "ACGGGTCTCTCAAACG" "ACGGGTCTCTGGCGTG"
## [712] "ACGTCAAAGCAATCTC" "ACGTCAAAGTCTTGCA" "ACGTCAAAGTGGGTTG"
## [715] "ACGTCAACAATCGGTT" "ACGTCAAGTCGAATCT" "ACGTCAAGTGAGTGAC"
## [718] "ACGTCAAGTGCACCAC" "ACGTCAATCACGAAGG" "ACGTCAATCAGTGCAT"
## [721] "ACGTCAATCAGTTGAC" "ACGTCAATCATCGGAT" "ACGTCAATCCAAAGTC"
## [724] "ACGTCAATCCGAAGAG" "ACGTCAATCTAACTTC" "ACGTCAATCTGATACG"
## [727] "ACGTCAATCTGCCCTA" "ACTATCTAGCAACGGT" "ACTATCTAGTAGCGGT"
## [730] "ACTATCTCAATGCCAT" "ACTATCTCAGATAATG" "ACTATCTCATAGACTC"
## [733] "ACTATCTCATTCGACA" "ACTATCTGTGTAATGA" "ACTATCTGTTGGTGGA"
## [736] "ACTATCTTCACGCATA" "ACTATCTTCAGCACAT" "ACTATCTTCATGTCTT"
## [739] "ACTGAACAGAAGGACA" "ACTGAACAGGGTCTCC" "ACTGAACCAATGAAAC"
## [742] "ACTGAACCACGCCAGT" "ACTGAACCACTTCTGC" "ACTGAACCAGCTGCAC"
## [745] "ACTGAACCAGGCTCAC" "ACTGAACGTACTTAGC" "ACTGAACGTATGGTTC"
## [748] "ACTGAACGTTCGCGAC" "ACTGAACGTTTGCATG" "ACTGAACTCACAAACC"
## [751] "ACTGAACTCCATGCTC" "ACTGAGTAGAAGAAGC" "ACTGAGTAGCACCGCT"
## [754] "ACTGAGTAGGAGTACC" "ACTGAGTAGGCATGGT" "ACTGAGTCAACTGGCC"
## [757] "ACTGAGTCACACCGAC" "ACTGAGTCATAGAAAC" "ACTGAGTCATATGGTC"
## [760] "ACTGAGTCATCCGTGG" "ACTGAGTGTCAACTGT" "ACTGAGTGTCAGAAGC"
## [763] "ACTGAGTGTGGACGAT" "ACTGAGTGTGTGACCC" "ACTGAGTTCGGTCCGA"
## [766] "ACTGATGAGAAACGAG" "ACTGATGAGACAAGCC" "ACTGATGAGCGATGAC"
## [769] "ACTGATGAGGTAAACT" "ACTGATGAGTAACCCT" "ACTGATGCACTCGACG"
## [772] "ACTGATGCAGGTCTCG" "ACTGATGGTCTCTCGT" "ACTGATGGTTCACCTC"
## [775] "ACTGATGGTTCTGAAC" "ACTGATGTCCAGGGCT" "ACTGATGTCCGCGGTA"
## [778] "ACTGATGTCTCGCATC" "ACTGCTCAGTTACGGG" "ACTGCTCCAAACTGTC"
## [781] "ACTGCTCCAAGTTCTG" "ACTGCTCCACCTCGTT" "ACTGCTCCACTTGGAT"
## [784] "ACTGCTCCAGCAGTTT" "ACTGCTCGTGGTCCGT" "ACTGCTCTCAGAGGTG"
## [787] "ACTGCTCTCCCGGATG" "ACTGCTCTCCGCGCAA" "ACTGCTCTCTGAGTGT"
## [790] "ACTGTCCAGACAGACC" "ACTGTCCAGAGATGAG" "ACTGTCCAGGGAACGG"
## [793] "ACTGTCCAGTTGTCGT" "ACTGTCCCACCTATCC" "ACTGTCCCAGCATGAG"
## [796] "ACTGTCCGTCAGCTAT" "ACTGTCCGTCCGTGAC" "ACTGTCCTCATTGCCC"
## [799] "ACTGTCCTCGAACTGT" "ACTGTCCTCTAACTGG" "ACTTACTAGAGGTAGA"
## [802] "ACTTACTAGTCTTGCA" "ACTTACTAGTGTCCAT" "ACTTACTCAAGCTGAG"
## [805] "ACTTACTCACATCCAA" "ACTTACTCACGGTAAG" "ACTTACTGTAAACGCG"
## [808] "ACTTACTGTAGCCTAT" "ACTTACTGTCAAAGAT" "ACTTACTGTTTGACAC"
## [811] "ACTTACTTCACAGTAC" "ACTTACTTCAGGCGAA" "ACTTACTTCATCACCC"
## [814] "ACTTGTTAGCGCTCCA" "ACTTGTTAGGCACATG" "ACTTGTTAGGTGCAAC"
## [817] "ACTTGTTCAATGGTCT" "ACTTGTTCACGCTTTC" "ACTTGTTCACGTCTCT"
## [820] "ACTTGTTCAGACGCTC" "ACTTGTTCAGTCAGAG" "ACTTGTTCATCCCACT"
## [823] "ACTTGTTCATCCCATC" "ACTTGTTCATGAACCT" "ACTTGTTGTCCGAGTC"
## [826] "ACTTGTTGTCGAATCT" "ACTTGTTGTCGAGATG" "ACTTGTTGTCTCTCTG"
## [829] "ACTTGTTGTGCTGTAT" "ACTTGTTGTTGGGACA" "ACTTGTTGTTGTCTTT"
## [832] "ACTTGTTTCCACTCCA" "ACTTTCAAGCAGCGTA" "ACTTTCAAGCGTTTAC"
## [835] "ACTTTCAAGCTAGGCA" "ACTTTCAAGCTCCTTC" "ACTTTCACAAACGCGA"
## [838] "ACTTTCACAGACTCGC" "ACTTTCACAGTCAGCC" "ACTTTCACATTGTGCA"
## [841] "ACTTTCAGTACTTAGC" "ACTTTCAGTACTTCTT" "ACTTTCAGTCTAAACC"
## [844] "ACTTTCAGTGTAACGG" "ACTTTCATCAACACGT" "ACTTTCATCCACGTTC"
## [847] "AGAATAGAGATGTTAG" "AGAATAGAGCCAGGAT" "AGAATAGAGCTCAACT"
## [850] "AGAATAGAGGAGTACC" "AGAATAGAGGTAAACT" "AGAATAGAGGTCGGAT"
## [853] "AGAATAGAGTGGGTTG" "AGAATAGCAACGCACC" "AGAATAGCAAGGTGTG"
## [856] "AGAATAGCACATGACT" "AGAATAGCACCCAGTG" "AGAATAGCATAAAGGT"
## [859] "AGAATAGCATAGAAAC" "AGAATAGCATGCCTTC" "AGAATAGGTACTTAGC"
## [862] "AGAATAGGTTCAGACT" "AGAATAGTCACCTCGT" "AGAATAGTCAGCTCTC"
## [865] "AGAATAGTCCTATTCA" "AGACGTTAGACTGGGT" "AGACGTTAGGCCCTCA"
## [868] "AGACGTTAGGTAAACT" "AGACGTTAGTGTTTGC" "AGACGTTCAGCTCCGA"
## [871] "AGACGTTGTAGGACAC" "AGACGTTGTGGTACAG" "AGACGTTTCAGTTAGC"
## [874] "AGACGTTTCCGTACAA" "AGACGTTTCTGCAAGT" "AGACGTTTCTTCCTTC"
## [877] "AGAGCGAAGATCCCGC" "AGAGCGAAGATCCTGT" "AGAGCGAAGCAGATCG"
## [880] "AGAGCGAAGTCCGGTC" "AGAGCGACAAAGCAAT" "AGAGCGACAATGGAAT"
## [883] "AGAGCGACATATGCTG" "AGAGCGACATCACAAC" "AGAGCGACATGGAATA"
## [886] "AGAGCGAGTACGACCC" "AGAGCGAGTCATGCAT" "AGAGCGAGTTGTACAC"
## [889] "AGAGCGATCACCGTAA" "AGAGCGATCAGCTTAG" "AGAGCGATCGGCGGTT"
## [892] "AGAGCGATCGGCTTGG" "AGAGCGATCTGTCTCG" "AGAGCTTAGACTAGGC"
## [895] "AGAGCTTAGCCACGTC" "AGAGCTTAGTCGTTTG" "AGAGCTTAGTGGGCTA"
## [898] "AGAGCTTCAAGTACCT" "AGAGCTTCACAGCCCA" "AGAGCTTCACCCAGTG"
## [901] "AGAGCTTCACGCTTTC" "AGAGCTTCAGTATCTG" "AGAGCTTCATAGTAAG"
## [904] "AGAGCTTGTCTAAACC" "AGAGCTTGTGCTAGCC" "AGAGCTTGTGGCAAAC"
## [907] "AGAGCTTGTGGTACAG" "AGAGCTTTCACTATTC" "AGAGCTTTCAGAAATG"
## [910] "AGAGCTTTCAGCACAT" "AGAGCTTTCCTCGCAT" "AGAGTGGAGAGGTAGA"
## [913] "AGAGTGGAGCCCGAAA" "AGAGTGGAGTCATGCT" "AGAGTGGAGTGGTCCC"
## [916] "AGAGTGGAGTGTACGG" "AGAGTGGCACATAACC" "AGAGTGGCACCGAAAG"
## [919] "AGAGTGGCAGCGTTCG" "AGAGTGGCAGGACCCT" "AGAGTGGCATCGATTG"
## [922] "AGAGTGGGTAGTGAAT" "AGAGTGGGTATAATGG" "AGAGTGGTCCCGACTT"
## [925] "AGAGTGGTCTACTTAC" "AGAGTGGTCTGTCAAG" "AGATCTGAGAGGTAGA"
## [928] "AGATCTGAGCAGGTCA" "AGATCTGAGCCAACAG" "AGATCTGAGGATCGCA"
## [931] "AGATCTGAGGGATCTG" "AGATCTGAGGGCTCTC" "AGATCTGAGGTGATAT"
## [934] "AGATCTGAGTACGTAA" "AGATCTGAGTTCGCAT" "AGATCTGCAAACAACA"
## [937] "AGATCTGCACATGACT" "AGATCTGGTAAGAGGA" "AGATCTGTCAGTTCGA"
## [940] "AGATCTGTCGCCATAA" "AGATCTGTCGCTTAGA" "AGATTGCAGAAACCAT"
## [943] "AGATTGCAGAGGTACC" "AGATTGCAGATAGTCA" "AGATTGCCACGGTTTA"
## [946] "AGATTGCCAGGGTATG" "AGATTGCCATCACGTA" "AGATTGCGTACATGTC"
## [949] "AGATTGCGTCCAGTAT" "AGATTGCGTCCGTGAC" "AGATTGCTCAGTGCAT"
## [952] "AGATTGCTCATGCATG" "AGATTGCTCGGCGGTT" "AGCAGCCAGAAACCAT"
## [955] "AGCAGCCAGACCTTTG" "AGCAGCCAGACGACGT" "AGCAGCCAGATGTTAG"
## [958] "AGCAGCCAGCACCGTC" "AGCAGCCAGTGGTAAT" "AGCAGCCCAAACCCAT"
## [961] "AGCAGCCCAGATGGCA" "AGCAGCCCATCACGAT" "AGCAGCCGTACTTAGC"
## [964] "AGCAGCCGTCCGAAGA" "AGCAGCCGTCGCTTCT" "AGCAGCCGTGCAGTAG"
## [967] "AGCAGCCGTTCCCGAG" "AGCAGCCGTTTAGGAA" "AGCAGCCGTTTGTTTC"
## [970] "AGCAGCCTCCTTGCCA" "AGCAGCCTCGTCGTTC" "AGCAGCCTCTGGAGCC"
## [973] "AGCATACAGTTCGATC" "AGCATACCACCACGTG" "AGCATACCACGGATAG"
## [976] "AGCATACCAGCTATTG" "AGCATACGTCCTCTTG" "AGCATACGTTAAGGGC"
## [979] "AGCATACGTTACTGAC" "AGCATACGTTAGATGA" "AGCATACTCATCGCTC"
## [982] "AGCATACTCCGCATCT" "AGCATACTCGAACTGT" "AGCATACTCTAACTTC"
## [985] "AGCATACTCTCGGACG" "AGCCTAAAGCCCAATT" "AGCCTAAAGGACATTA"
## [988] "AGCCTAAAGTACGTTC" "AGCCTAAAGTCGATAA" "AGCCTAAAGTCTTGCA"
## [991] "AGCCTAACAAGCCTAT" "AGCCTAACACGTCTCT" "AGCCTAACAGCCTGTG"
## [994] "AGCCTAACATCAGTCA" "AGCCTAAGTATCTGCA" "AGCCTAAGTCGGCTCA"
## [997] "AGCCTAAGTTATCCGA" "AGCCTAATCAGTACGT" "AGCCTAATCCCTTGTG"
## [1000] "AGCCTAATCGTTTGCC"
## [ reached getOption("max.print") -- omitted 6109 entries ]# One can pull multiple values from the data frame at any time
head(x = seurat@meta.data[c('nCount_RNA', 'nFeature_RNA')])## nCount_RNA nFeature_RNA
## AAACCTGAGCTAGTCT 3605 1184
## AAACCTGAGGGCACTA 3828 1387
## AAACCTGAGTACGTTC 6457 1784
## AAACCTGAGTCCGGTC 3075 1092
## AAACCTGCACCAGGTC 9399 2625
## AAACCTGCACCTCGTT 48838 5602# The $ sigil can only pull bit of meta data at a time; however, tab-autocompletion
# has been enabled for the $ sigil, making it ideal for interactive use
head(x = seurat@meta.data$nFeature_RNA)## [1] 1184 1387 1784 1092 2625 5602# Passing `drop = TRUE` will turn the meta data into a names vector
# with each entry being named for the cell it corresponds to
head(x = seurat@meta.data['nFeature_RNA', drop = TRUE])## Warning in `[.data.frame`(seurat@meta.data, "nFeature_RNA", drop
## = TRUE): 'drop' argument will be ignored## nFeature_RNA
## AAACCTGAGCTAGTCT 1184
## AAACCTGAGGGCACTA 1387
## AAACCTGAGTACGTTC 1784
## AAACCTGAGTCCGGTC 1092
## AAACCTGCACCAGGTC 2625
## AAACCTGCACCTCGTT 56024.4.1.4 Methods
Methods for the Seurat class can be found with the following:
## [1] [ [[
## [3] [[<- $
## [5] $<- AddMetaData
## [7] as.CellDataSet as.loom
## [9] as.SingleCellExperiment colMeans
## [11] colSums Command
## [13] DefaultAssay DefaultAssay<-
## [15] dim dimnames
## [17] droplevels Embeddings
## [19] FindClusters FindMarkers
## [21] FindNeighbors FindVariableFeatures
## [23] GetAssay GetAssayData
## [25] HVFInfo Idents
## [27] Idents<- Key
## [29] levels levels<-
## [31] Loadings merge
## [33] Misc Misc<-
## [35] names NormalizeData
## [37] OldWhichCells Project
## [39] Project<- RenameCells
## [41] RenameIdents ReorderIdent
## [43] rowMeans rowSums
## [45] RunALRA RunCCA
## [47] RunICA RunLSI
## [49] RunPCA RunTSNE
## [51] RunUMAP ScaleData
## [53] ScoreJackStraw SetAssayData
## [55] SetIdent show
## [57] StashIdent Stdev
## [59] subset SubsetData
## [61] Tool Tool<-
## [63] VariableFeatures VariableFeatures<-
## [65] WhichCells
## see '?methods' for accessing help and source codeYou can also list all functions in the Seurat package by using:
## [1] "AddMetaData"
## [2] "AddModuleScore"
## [3] "ALRAChooseKPlot"
## [4] "as.CellDataSet"
## [5] "as.Graph"
## [6] "as.loom"
## [7] "as.Seurat"
## [8] "as.SingleCellExperiment"
## [9] "as.sparse"
## [10] "Assays"
## [11] "AugmentPlot"
## [12] "AverageExpression"
## [13] "BarcodeInflectionsPlot"
## [14] "BlackAndWhite"
## [15] "BlueAndRed"
## [16] "BoldTitle"
## [17] "BuildClusterTree"
## [18] "CalculateBarcodeInflections"
## [19] "CaseMatch"
## [20] "cc.genes"
## [21] "cc.genes.updated.2019"
## [22] "CellCycleScoring"
## [23] "Cells"
## [24] "CellsByIdentities"
## [25] "CellScatter"
## [26] "CellSelector"
## [27] "CollapseEmbeddingOutliers"
## [28] "CollapseSpeciesExpressionMatrix"
## [29] "ColorDimSplit"
## [30] "CombinePlots"
## [31] "Command"
## [32] "CreateAssayObject"
## [33] "CreateDimReducObject"
## [34] "CreateGeneActivityMatrix"
## [35] "CreateSeuratObject"
## [36] "CustomDistance"
## [37] "CustomPalette"
## [38] "DarkTheme"
## [39] "DefaultAssay"
## [40] "DefaultAssay<-"
## [41] "DietSeurat"
## [42] "DimHeatmap"
## [43] "DimPlot"
## [44] "DoHeatmap"
## [45] "DotPlot"
## [46] "ElbowPlot"
## [47] "Embeddings"
## [48] "ExpMean"
## [49] "ExportToCellbrowser"
## [50] "ExpSD"
## [51] "ExpVar"
## [52] "FeatureLocator"
## [53] "FeaturePlot"
## [54] "FeatureScatter"
## [55] "FetchData"
## [56] "FindAllMarkers"
## [57] "FindClusters"
## [58] "FindConservedMarkers"
## [59] "FindIntegrationAnchors"
## [60] "FindMarkers"
## [61] "FindNeighbors"
## [62] "FindTransferAnchors"
## [63] "FindVariableFeatures"
## [64] "FontSize"
## [65] "GeneSymbolThesarus"
## [66] "GetAssay"
## [67] "GetAssayData"
## [68] "GetIntegrationData"
## [69] "GetResidual"
## [70] "HoverLocator"
## [71] "HTODemux"
## [72] "HTOHeatmap"
## [73] "HVFInfo"
## [74] "Idents"
## [75] "Idents<-"
## [76] "IntegrateData"
## [77] "IsGlobal"
## [78] "JackStraw"
## [79] "JackStrawPlot"
## [80] "JS"
## [81] "JS<-"
## [82] "Key"
## [83] "Key<-"
## [84] "L2CCA"
## [85] "L2Dim"
## [86] "LabelClusters"
## [87] "LabelPoints"
## [88] "Loadings"
## [89] "Loadings<-"
## [90] "LocalStruct"
## [91] "LogNormalize"
## [92] "LogSeuratCommand"
## [93] "LogVMR"
## [94] "MetaFeature"
## [95] "MinMax"
## [96] "Misc"
## [97] "Misc<-"
## [98] "MixingMetric"
## [99] "MULTIseqDemux"
## [100] "NoAxes"
## [101] "NoGrid"
## [102] "NoLegend"
## [103] "NormalizeData"
## [104] "OldWhichCells"
## [105] "pbmc_small"
## [106] "PCAPlot"
## [107] "PCASigGenes"
## [108] "PCHeatmap"
## [109] "PercentageFeatureSet"
## [110] "PlotClusterTree"
## [111] "PolyDimPlot"
## [112] "PolyFeaturePlot"
## [113] "PrepSCTIntegration"
## [114] "Project"
## [115] "Project<-"
## [116] "ProjectDim"
## [117] "PurpleAndYellow"
## [118] "Read10X"
## [119] "Read10X_h5"
## [120] "ReadAlevin"
## [121] "ReadAlevinCsv"
## [122] "ReadH5AD"
## [123] "Reductions"
## [124] "RegroupIdents"
## [125] "RelativeCounts"
## [126] "RenameAssays"
## [127] "RenameCells"
## [128] "RenameIdents"
## [129] "ReorderIdent"
## [130] "RestoreLegend"
## [131] "RidgePlot"
## [132] "RotatedAxis"
## [133] "RowMergeSparseMatrices"
## [134] "RunALRA"
## [135] "RunCCA"
## [136] "RunICA"
## [137] "RunLSI"
## [138] "RunPCA"
## [139] "RunTSNE"
## [140] "RunUMAP"
## [141] "SampleUMI"
## [142] "ScaleData"
## [143] "ScoreJackStraw"
## [144] "SCTransform"
## [145] "SelectIntegrationFeatures"
## [146] "SetAssayData"
## [147] "SetIdent"
## [148] "SetIntegrationData"
## [149] "SeuratAxes"
## [150] "SeuratTheme"
## [151] "SpatialTheme"
## [152] "SplitObject"
## [153] "StashIdent"
## [154] "Stdev"
## [155] "StopCellbrowser"
## [156] "SubsetByBarcodeInflections"
## [157] "SubsetData"
## [158] "TF.IDF"
## [159] "Tool"
## [160] "Tool<-"
## [161] "TopCells"
## [162] "TopFeatures"
## [163] "TransferData"
## [164] "TSNEPlot"
## [165] "UMAPPlot"
## [166] "UpdateSeuratObject"
## [167] "UpdateSymbolList"
## [168] "VariableFeaturePlot"
## [169] "VariableFeatures"
## [170] "VariableFeatures<-"
## [171] "VizDimLoadings"
## [172] "VlnPlot"
## [173] "WhichCells"
## [174] "WhiteBackground"4.5 Preprocessing step 1 : Filter out low-quality cells
The Seurat object initialization step above only considered cells that expressed at least 350 genes. Additionally, we would like to exclude cells that are damaged. A common metric to judge this (although by no means the only one) is the relative expression of mitochondrially derived genes. When the cells apoptose due to stress, their mitochondria becomes leaky and there is widespread RNA degradation. Thus a relative enrichment of mitochondrially derived genes can be a tell-tale sign of cell stress. Here, we compute the proportion of transcripts that are of mitochondrial origin for every cell (percent.mt), and visualize its distribution as a violin plot. We also use the FeatureScatter function to observe how percent.mt correlates with other metrics.
# The number of genes and UMIs (nFeature_RNA nCount_RNA) are automatically calculated
# for every object by Seurat. For non-UMI data, nCount_RNA represents the sum of
# the non-normalized values within a cell We calculate the percentage of
# mitochondrial genes here and store it in percent.mt using AddMetaData.
# We use GetAssayData(object = seurat, slot = 'data') since this represents non-transformed and
# non-log-normalized counts The % of UMI mapping to MT-genes is a common
# scRNA-seq QC metric.
# The [[ operator can add columns to object metadata. This is a great place to stash QC stats
seurat[["percent.mt"]] <- PercentageFeatureSet(object = seurat, pattern = "^MT-")
# PercentageFeatureSet adds columns to object@meta.data, and is a great place to stash QC stats.
# This also allows us to plot the metadata values using the Seurat's VlnPlot().
head(seurat@meta.data) # Before adding## orig.ident nCount_RNA nFeature_RNA percent.mt
## AAACCTGAGCTAGTCT 10X_NSCLC 3605 1184 20.832178
## AAACCTGAGGGCACTA 10X_NSCLC 3828 1387 3.448276
## AAACCTGAGTACGTTC 10X_NSCLC 6457 1784 2.865108
## AAACCTGAGTCCGGTC 10X_NSCLC 3075 1092 6.276423
## AAACCTGCACCAGGTC 10X_NSCLC 9399 2625 3.202468
## AAACCTGCACCTCGTT 10X_NSCLC 48838 5602 2.321962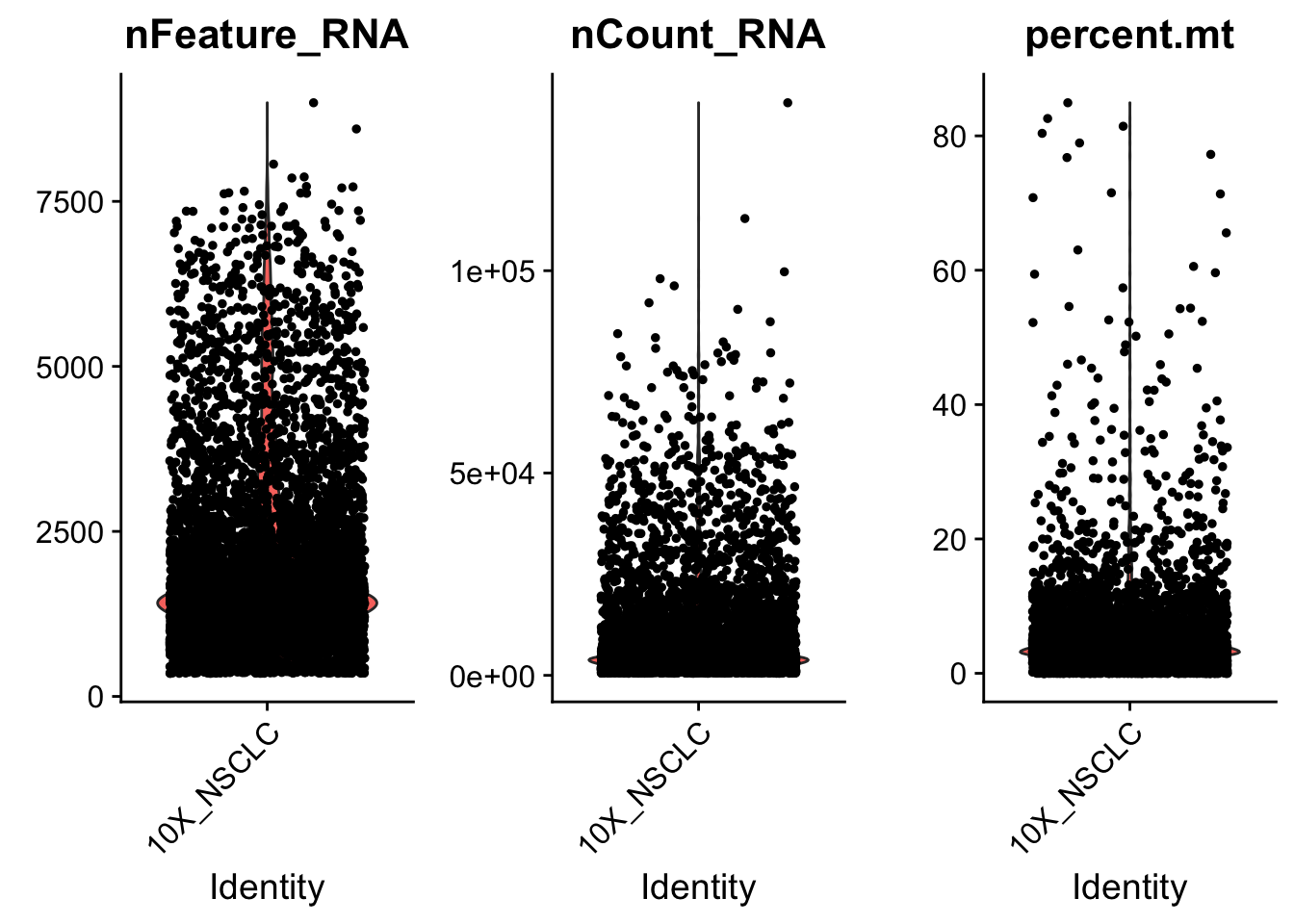
Here we calculated the percent mitochondrial reads and added it to the Seurat object in the slot named meta.data. This allowed us to plot using the violin plot function provided by Seurat.
A third metric we use is the number of house keeping genes expressed in a cell. These genes reflect commomn processes active in a cell and hence are a good global quality measure. They are also abundant and are usually steadliy expressed in cells, thus less sensitive to the high dropout.
# Load the the list of house keeping genes
hkgenes <- read.table(paste0(dirname, "housekeepers.txt"), skip = 2)
hkgenes <- as.vector(hkgenes$V1)
# remove hkgenes that were not found
hkgenes.found <- which(toupper(rownames(seurat@assays$RNA@data)) %in% hkgenes)Possible task: Feel like challenging yourself? write the code to do the following: 1. Sum the number of detected house keeping genes for each cell 2. Add this information as meta data to seurat 3. plot all metrics: “nFeature_RNA”, “nCount_RNA”, “percent.mt”,“n.exp.hkgenes” using VlnPlot 4. Scroll down to see if you got it!
If you feel like going through a more guided version, scroll down and follow the instructions.
Alternative task: Sum the number of detected house keeping genes for each cell, then add this to the meta data
#### n.expressed.hkgenes <- ?(seurat@data[hkgenes.found, ] > ?)
#### seurat <- AddMetaData(object = ?, ? = ?, col.name = "n.exp.hkgenes")
n.expressed.hkgenes <- Matrix::colSums(seurat@assays$RNA@data[hkgenes.found, ] > 0)
seurat <- AddMetaData(object = seurat, metadata = n.expressed.hkgenes, col.name = "n.exp.hkgenes")
VlnPlot(object = seurat, features = c("nFeature_RNA", "nCount_RNA", "percent.mt", "n.exp.hkgenes"), ncol = 2)
Is there a correlation between the measurements? For example, number of UMIs with number of genes? Possible task: Feel like challenging yourself? write the code to do the following: Can you plot the nGene vs nUMI (hint:GenePlot)? What is the correlation? Do you see a strange subpopulation? What do you think happened with these cells?
Scroll down to see the command
Alternative task: Can you plot the nFeature_RNA vs nCount_RNA (hint:FeatureScatter)? What is the correlation? Do you see a strange subpopulation? What do you think happened with these cells?
# FeatureScatter is typically used to visualize feature-feature relationships, but can be used
# for anything calculated by the object, i.e. columns in object metadata, PC scores etc.
plot1 <- FeatureScatter(seurat, feature1 = "nCount_RNA", feature2 = "percent.mt")
plot2 <- FeatureScatter(seurat, feature1 = "nCount_RNA", feature2 = "nFeature_RNA")
CombinePlots(plots = list(plot1, plot2))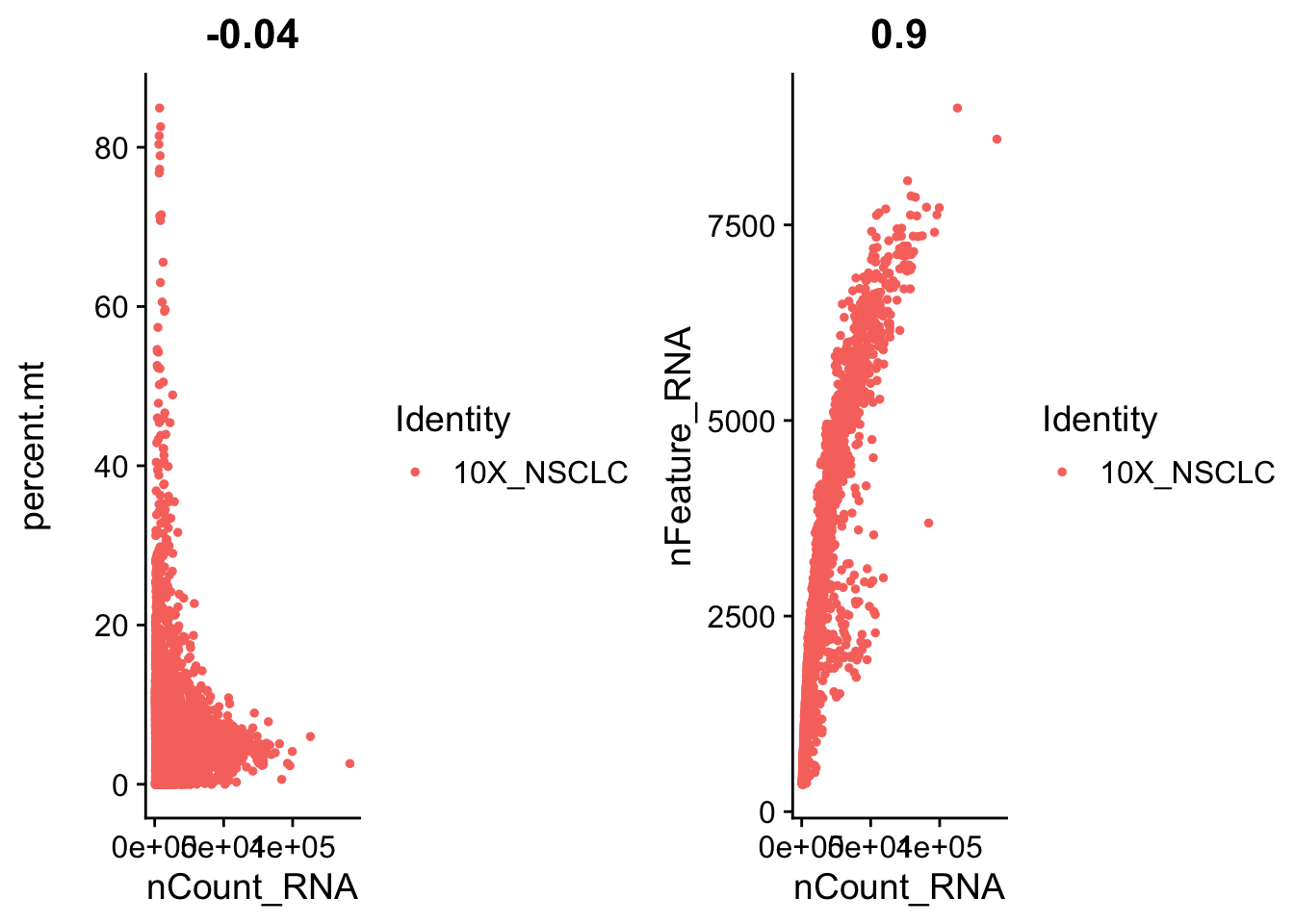
4.6 Examine contents of Seurat object
These are the slots in the Seurat object. Some of the slots are automatically updated by Seurat as you move through analysis. Take a moment to look through the information, knowing the slots allow you to leverage work Seurat has already done for you.
Here we plot the number of genes per cell by what Seurat calls orig.ident. Identity is a concept that is used in the Seurat object to refer to the cell identity. In this case, the cell identity is 10X_NSCLC, but after we cluster the cells, the cell identity will be whatever cluster the cell belongs to. We will see how identity updates as we go throught the analysis.
Next, let’s filter the cells based on the quality control metrics. Filter based on: 1. nFeature_RNA 2. percent.mt 3. n.exp.hkgenes
Task: Change the thresholds to what you think they should be according to the violin plots
# seurat <- SubsetData(object = seurat, subset.names = c("nFeature_RNA", "percent.mito","n.exp.hkgenes"), low.thresholds = c(350, -Inf,55), high.thresholds = c(5000, 0.1, Inf))
seurat <- subset(seurat, nFeature_RNA < 5000)
seurat <- subset(seurat, nFeature_RNA > 350)
seuart <- subset(seurat, n.exp.hkgenes > 55)
seuart <- subset(seurat, percent.mt < 10)How many cells are you left with?
4.6.1 Preprocessing step 2 : Expression normalization
After removing unwanted genes cells from the dataset, the next step is to normalize the data. By default, we employ a global-scaling normalization method “LogNormalize” that normalizes the gene expression measurements for each cell by the total expression, multiplies this by a scale factor (10,000 by default), and log-transforms the result. There have been many methods to normalize the data, but this is the simplest and the most intuitive. The division by total expression is done to change all expression counts to a relative measure, since experience has suggested that technical factors (e.g. capture rate, efficiency of reverse transcription) are largely responsible for the variation in the number of molecules per cell, although genuine biological factors (e.g. cell cycle stage, cell size) also play a smaller, but non-negligible role. The log-transformation is a commonly used transformation that has many desirable properties, such as variance stabilization (can you think of others?).
Well there you have it! A filtered and normalized gene-expression data set. A great accomplishment for your first dive into scRNA-Seq analysis. Well done!
4.7 Detection of variable genes across the single cells
Seurat calculates highly variable genes and focuses on these for downstream analysis. FindVariableFeatures calculates the average expression and dispersion for each gene, places these genes into bins, and then calculates a z-score for dispersion within each bin. This helps control for the relationship between variability and average expression. This function is unchanged from (Macosko et al.), but new methods for variable gene expression identification are coming soon. We suggest that users set these parameters to mark visual outliers on the dispersion plot, but the exact parameter settings may vary based on the data type, heterogeneity in the sample, and normalization strategy. The parameters here identify ~3,000 variable genes, and represent typical parameter settings for UMI data that is normalized to a total of 1e4 molecules.
### seurat <- FindVariableFeatures(object = seurat, selection.method = ?, nfeatures = ?)
### Task: ?FindVariableFeatures into the console to read about different selection methods
seurat <- FindVariableFeatures(object = seurat, selection.method = "vst", nfeatures = 2000)
# Identify the 10 most highly variable genes
top10 <- head(VariableFeatures(seurat), 10)We can see the Seurat object slots have updated for the FindVariableFetures section. Let’s use the slot to see how many variable genes we found.
Task: how does changing the parameters for find variable genes function changes the number of the found genes? Play with the parameters - what makes the function find more variable genes? less?
seurat <- FindVariableFeatures(object = seurat, selection.method = "vst", nfeatures = 2000,
mean.function = ExpMean, dispersion.function = LogVMR,
num.bin = 40,
mean.cutoff = c(0.0125, 1),
dispersion.cutoff = c(0, 0.5))
## Check number of variable genes
length(seurat@assays$RNA@var.features)seurat <- FindVariableFeatures(object = seurat, selection.method = "vst", nfeatures = 2000,
mean.function = ExpMean, dispersion.function = LogVMR,
num.bin = 10,
mean.cutoff = c(0.0125, 1),
dispersion.cutoff = c(0, 0.5))
## Check number of variable genes
length(seurat@assays$RNA@var.features)seurat <- FindVariableFeatures(object = seurat, selection.method = ??, nfeatures = 2000,
mean.function = ExpMean, dispersion.function = LogVMR,
num.bin = ??,
mean.cutoff = c(??, ??),
dispersion.cutoff = c(??, ??))
## Check number of variable genes
length(seurat@assays$RNA@var.features)seurat <- FindVariableFeatures(object = seurat, selection.method = ??, nfeatures = 2000,
mean.function = ExpMean, dispersion.function = LogVMR,
num.bin = ??,
mean.cutoff = c(??, ??),
dispersion.cutoff = c(??, ??))
## Check number of variable genes
length(seurat@assays$RNA@var.features)seurat <- FindVariableFeatures()
## Check number of variable genes
length(seurat@assays$RNA@var.features)# plot variable features with and without labels
plot1 <- VariableFeaturePlot(seurat)
plot2 <- LabelPoints(plot = plot1, points = top10, repel = TRUE)## When using repel, set xnudge and ynudge to 0 for optimal results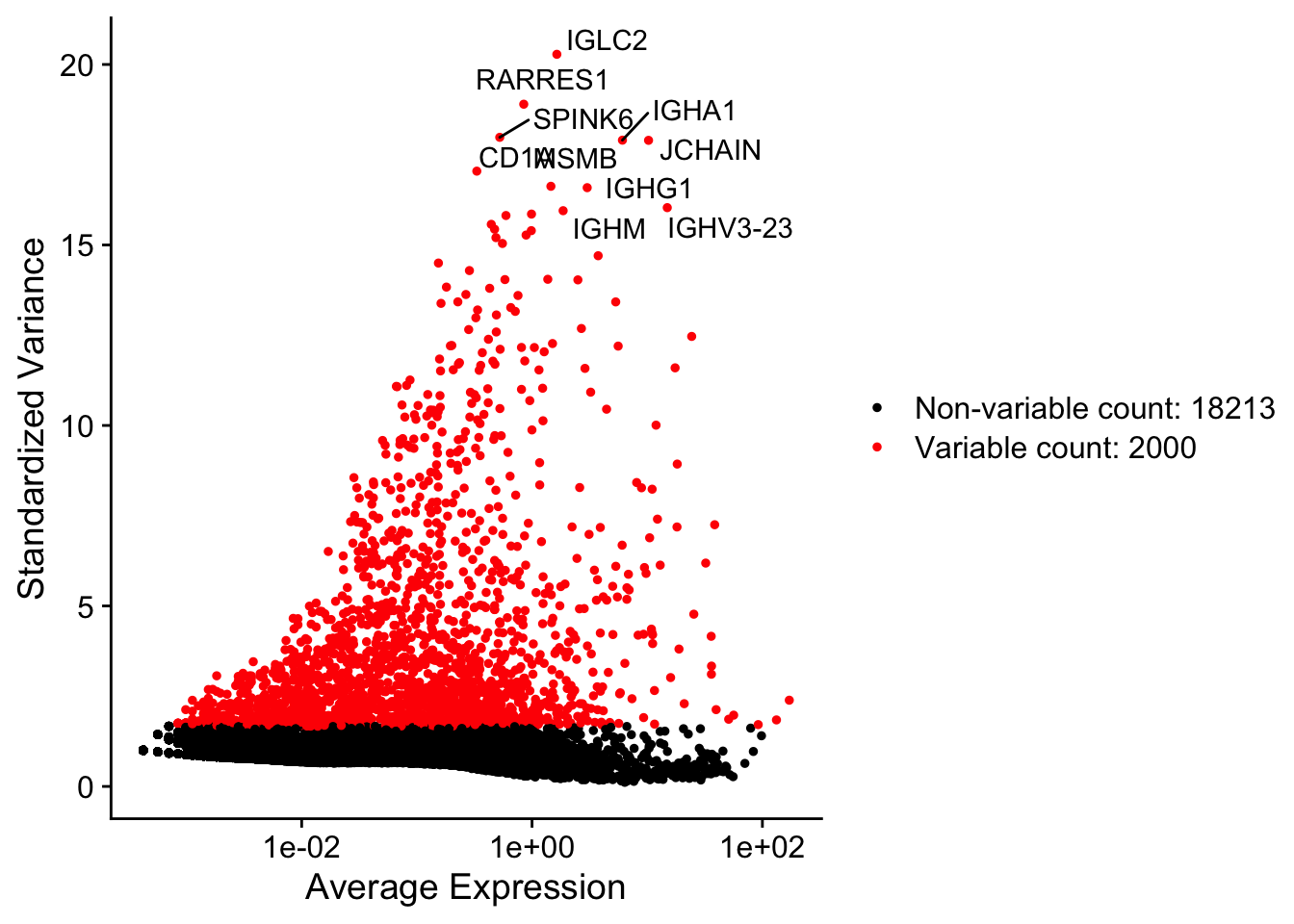
4.8 Gene set expression across cells
Sometimes we want to ask what is the expression of a set of a genes across cells. This set of genes may make up a gene expression program we are interested in. Another benefit at looking at gene sets is it reduces the effects of drop outs.
Below, we look at genes involved in: T cells, the cell cycle and the stress signature upon cell dissociation. We calculate these genes average expression levels on the single cell level, while controlling for technical effects.
# Read in a list of cell cycle markers, from Tirosh et al, 2015.
# We can segregate this list into markers of G2/M phase and markers of S phase.
s.genes <- Seurat::cc.genes$s.genes
s.genes <- s.genes[s.genes %in% rownames(seurat)] # genes in dataset
g2m.genes <- Seurat::cc.genes$g2m.genes
g2m.genes <- g2m.genes[g2m.genes %in% rownames(seurat)] # genes in dataset
seurat <- CellCycleScoring(object = seurat, s.features = s.genes, g2m.features = g2m.genes, set.ident = TRUE)Task: Use markers for dissociation to calculate dissociation score
# Genes upregulated during dissociation of tissue into single cells.
genes.dissoc <- c("ATF3", "BTG2", "CEBPB", "CEBPD", "CXCL3", "CXCL2", "CXCL1", "DNAJA1", "DNAJB1", "DUSP1",
"EGR1", "FOS", "FOSB", "HSP90AA1", "HSP90AB1", "HSPA1A", "HSPA1B", "HSPA1A", "HSPA1B",
"HSPA8", "HSPB1", "HSPE1", "HSPH1", "ID3", "IER2", "JUN", "JUNB", "JUND", "MT1X", "NFKBIA",
"NR4A1", "PPP1R15A", "SOCS3", "ZFP36")
#### seurat <- ?(?, genes.list = list(?), ctrl.size = 20, enrich.name = "genes_dissoc")
seurat <- AddModuleScore(seurat, features = list(genes.dissoc), ctrl.size = 20, enrich.name = "genes_dissoc")Task: - Plot the correlation between number of genes and S score. - How do we know the name of these scores in the seurat meta data?
Bonus: Can you cluster the data based on the variable genes alone?
Congratulations! You can identify and visualize cell subsets and the marker genes that describe these cell subsets. This is a very powerful analysis pattern often seen in publications. Well done!